日本語には文字(漢字)が何万もあるので、1バイト(0〜255)では到底足りない。そこで、 2バイトで1文字を表現することにした。
2バイトを使うと、 256×256=65536種類の文字を本来表せる。
ここから前が1ビット目0
↓
0〜65535の整数と日本語の文字とを対応させるものに、 JIS コードというのがある。たとえば JIS コードで 16 進数で
21 22 は「、」、16 進数で 24 3d は「そ」、16 進数で 32 23 は「横」 ……。
しかし、日本においても、コンピュータは1バイト文字はASCII コードである。1バイト文字のASCIIコードと2バイト文字の JIS コードを混在させるとどうなるか?たとえば
32 23(16 進数)は「横」という 1文字の日本語文字でもあり、「2#」という 2文字の英数字でもある。
これは困る。
そこで、解決法のまず第一は、
1バイト文字と2バイト文字の混在を許さないというやり方がある。
しかし、これはコンピュータが細切れになった様々なデータの集合を扱う時代には有効だったかも知れないが、英数や日本語が混在するような、日常的な言語環境を反映したものとは言えない。
解決法の第二は、
「これ以降は JIS コード(2バイト)」「これ以降は ASCII コード(1バイト)」 という意味の特別なコード(制御コード)を加えるというものである。ASCII コードの0〜31 は文字以外の特別なコードに使うことになっていたので、このうちの2コードを2バイト文字開始と2バイト文字終了の符号とする。具体的に何番をどのコードに 割り当てるかは、いくつかの流儀がある。
しかし、データを入力する際に、ここからは1バイトここからは2バイトという注意を常にしなけれならないというのは、つらい。
第三の解決方法は、
ASCII コードでは 00〜ff のうち半分 (00〜) しか使っていないので、 80〜ff、つまり先頭ビットが 1 であるようなバイトがきたら、そのバイトと 次のバイトとがセットで日本語文字を表す、という解決法。この方法では、日本語文字は256×256=65536文字ではなく128(80〜ff)×256=32768文字しか最大表せない。このためには JIS コードを、1 バイト目の先頭ビットが必ず 1 になるように換算しなければなりませんが、JIS コードは 1バイト目も 2バイト目も先頭ビットが 0 なので、単にそれを 1 にするだけ。EUC (Extended Unix Code)。UNIX で広く用いられている。また、インターネットでの日本語文字取り扱いを考えるとき一応理解しておいた方がよい。
最後の方法は、EUC と同じ様な考え方で、半角カナも同時に使えるという方法。
半角カナ文字は、日本のコンピュータで広く使われている。歴史的には、日本語は半角カナしか扱えないコンピュータというのが先にあった(初期のダイレクトメールの宛名表記を想起されたい)。この半角カナのコードは、ASCII コードで使われていない a0 (16進数) から df (16進数) までに割り当てられている。

日本語文字の 1 バイト目に利用可能なのは 80 (16 進数) から 9f (16 進数) までと、e0 (16 進数) から ff (16 進数) まで。上の図で、■の部分である。日本語文字は 64(=32+32)×256=16384文字しか最大表現できない。ただ、換算方法は二カ所に分裂するので、EUC のような簡単なものにはなりえない。このコード表を シフト JIS または MS 漢字コード と呼ぶ。 シフト JIS は、MS-DOS、Windows、OS/2、Macintosh などで用いられている。
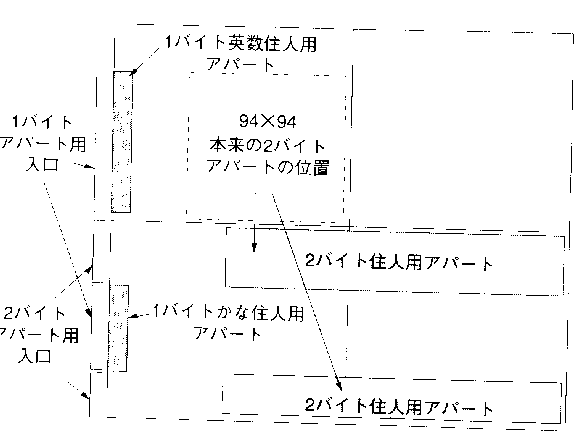
このシフトJISによって、1バイト文字(英数、半角カナ)と2バイト文字の完全な混用が可能となった。
そのかわり、漢字に割り当てられた文字コードのフィールドは狭く、かつ複雑になった。
http://kubota.rcpom.osaka-u.ac.jp/students/kubota/doc/data.html
伊藤英俊『漢字文化とコンピュータ』(中央公論社、1996)
を参考にしました。