WWW
サーバによる日本史データベースのマルチメディア化と公開に関する研究
課題番号
084080111996
年度~1998年度科学研究費補助金 基盤研究
(A)(2)
研 究 成 果 報 告 書
1999
年3月
研究代表者 加 藤 友 康
(東京大学史料編纂所教授)
目 次
2.3
WWWサーバを利用した歴史史料情報公開の今後の課題 鶴田 啓 57
1 研究の概要
1
研究課題名 WWWサーバによる日本史データベースのマルチメディア化 と公開に関する研究
2
研究種目・課題番号 基盤研究(A)(2) 08408011
3
研究期間 1996年度~1998年度
4
研究経費 1996年度 22,400千円1997
年度 6,000千円1998
年度 3,500千円
研究代表者 加 藤 友 康 東京大学史料編纂所教授
研究分担者 石 上 英 一 東京大学史料編纂所教授
保 立 道 久 東京大学史料編纂所教授
近 藤 成 一 東京大学史料編纂所助教授
横 山 伊 徳 東京大学史料編纂所助教授
鶴 田 啓 東京大学史料編纂所助教授
山 口 英 男 東京大学史料編纂所助教授
浅 見 雅 一 東京大学史料編纂所助手
渡 邉 正 男 東京大学史料編纂所助手
中 島 圭 一 東京大学史料編纂所助手
2 研究成果
2.1 研究の目的と成果の概要
加 藤 友 康
1.研究の目的
史料編纂所では、
1984年以来、日本史史料のデータベース構築に取り組み、本研究が開始された前年度の1995年度までに約50万件と200万字以 上のデータを蓄積してきた。1993年2月にはACOS3300/150Nとワークステーション(EWS 4800)を導入し、これらの上に東京大学史料編纂所歴史情報処理システム(SHIPS)とデータベースの移植を行なってきた。SHIPSデータベースのうち、「古文書目録データベース」「記録古文書フルテキストデータベース」「大日本史料索引データベース」「維新史料綱要データベース」「編年史料綱文データベース」などの利用環境の統合的整備を行ない、中世古文書を中心とするフルテキストデータベースの構築方法に関する研究も進めてきた。また科学研究費研究成果公開促進費によるデータの構築と公開を進め、これらのデータベースのうち「古文書目録データベース」「維新史料綱要データベース」を、学術情報センターを通じて、全国にオンライン公開するとともに、本研究所内においても一般公開の体制をとってきた。
さらに汎用機の上に構築されたデータベースを
UNIX環境で利用するための研究を行ない、SHIPS データベースのうち「維新史料綱要データベース」「編年史料綱文データベース」をワークステーションを介して利用できる環境を整えてきた。以上のような研究蓄積のうえに、本研究では次のような認識のもとに新しい課題を設定することとした。すなわち、日本史史料のデータベース化の事業は、これまでテキスト中心であったが、文字情報の研究と並ぶ資料としての画像情報の研究の必要性が指摘され、日本史史料のデータベースについても、画像情報をデータベース化することが求められるようになってきていることである。画像情報のデータベース化によって、第1に活字化された文献史料のテキストデータベースについて、文書の写真との連結によってテキストそのものの研究を一層進展させ、第2に画像情報そのもの(荘園絵図・肖像画・花押・錦絵など)についての独自の研究も深化させる条件を整えることが可能となるからである。
そこで、本研究の第1の目的として、蓄積されたテキスト情報と画像情報の連結によって、歴史史料としての文字情報の解析に際して、多用な情報を連関させうる条件を構築することとした。史料編纂所が所蔵する「影写本」のマイクロフィルムと「古文書目録データベース」、「維新史料」のマイクロフィルムと「維新史料綱要データベース」のハイパーテキストによる検索、前近代史料の調査とそこで撮影したマイクロフィルム蓄積の成果の公開など、
SHIPS データベースとの連結を図りながら、史料編纂所で構築したデータベースのマルチメディア化を行なうことである。第2の目的として、画像情報そのもののグラフィカルなデータ蓄積を進め、これを第1の成果と結びつけ、多面的な歴史情報として構築することとした。史料編纂所においては、これまで肖像画の画像データを蓄積しており、これ以外にも本研究所所蔵の貴重書、古代・中世の荘園絵図、文書の花押、摺物・古写真などの画像をデータベース化し、検索のシステムを構築することで、資料としての画像情報を対象とする研究の進展を可能にするためである。
第3の目的として、
WWWサーバ対応のデータベースとして歴史史料のデータベース構築を進めることとした。これまでテキストデータが中心であったデータベースの提供に対して、WWWサーバを介して画像情報とテキスト情報を効率的に公開するシステムを開発することにより、多面的な歴史情報の提供が可能となり、本研究所内の研究者の研究に寄与するだけでなく、国内外の日本史研究者もそれを利用することで多角的な研究を進めることができるからである。
2.研究の経過と成果の概要
1996
年度(1)
史料編纂所歴史情報処理システム(SHIPS)上のデータベース(「古文書目録データベース」「編年史料綱文データベース」「維新史料綱要データベース」「古文書フルテキストデータベース」「大日本史料索引データベース」「中世記録人名索引データベース」「諸家文書目録データベース(島津家)」など)を、ワークステーション(EWS 4800)上へ移植し、EWS 4800をWWWサーバとしてこのデータを検索可能とするシステムを確立した。(2)
「影写本の画像データ化」のために、「影写本マイクロフィルム台帳」のデータ入力を行ない、また本研究所の所蔵する「影写本マイクロフィルム」(35mmフィルム 870リール、約53万コマ)をデジタル画像化してCD-ROMを作成し、EWS 4800上のDBMSであるFuture Happinessによる「影写本データベース」検索と連動し、Netscape NavigatorおよびVIEWDIRETOR PRO2+を介して、WWWサーバによる検索結果を画像表示できるシステムを構築した。(3)
『東京大学史料編纂所図書目録』第二部和漢書写本編全10冊および同カード約1300枚のデータ入力を行ない、影写本・謄写本をはじめとする本研究所所蔵図書の目録データベースを構築し、「古文書目録データベース」の追加データ入力として、「入来院家文書」データの入力作業も行なった。(4)
日本関係海外史料マイクロフィルム目録のデータベース化の前提作業として、『Historical Documents Relating to JAPAN in Foreign Countries』Vols.14のデータ入力を行なった。1997
年度(1)
史料編纂所が所蔵する非刊行物系の史資料の目録データベースである所蔵史料目録データベースについて、公文書目録基準(森本祥子訳「国際標準記録史料記述:一般原則」『記録と史料』6(1995) 参照)をモデルとして、書目、冊次、細目の3階層構造をもつデータベースに再構築する作業を行なった。更に、SHIPSの将来計画を見通して、PCサーバ利用によるマルチユーザシステムとした。(2) 1996
年度に作成した「古文書目録データベース」・「古文書フルテキストデータベース」のデータに、1996年度にデジタル画像化しCD-ROMに保存した「影写本マイクロフィルム」のイメージデータを連結するためのHTMLタグを付与し、 WWWサーバを通じて、影写本画像のデータ公開のシステムを完成した。これにより、1997年6月より、『東寺百合文書』(京都府立総合資料館所蔵)の影写本等の画像データ公開を開始した。(3)
史料編纂所所蔵貴重書のデータベース入力を行ない、その画像データをフォトCDとして蓄積し、イメージデータのHTMLタグを付与し、 WWWサーバを通じて、史料編纂所所蔵「入来院家文書」のマルチメディアデータベースとして公開を行なった。(4)
「古文書フルテキストデータベース」でのデータ構築について、ハイパーテキスト形態をふくむものに改良し、現有の汎用機(AX7300)経由ではなく、直接にEWS 4800上のDBMSであるFuture Happinessに登録するシステムを開発を行なった。これにより、「古文書フルテキストデータベース」を、『大日本古記録』・『平安遺文』からなる「平安時代フルテキストデータベース」と、『大日本古文書』からなる「古文書フルテキストデータベース」の2つに分離した。1998
年度(1) 1996
年度にデジタル画像化しCD-ROMに保存した「影写本マイクロフィルム」のイメージデータについて、CD-ROMサーバから画像を読み出して表示させていたシステムを、より高速にまた安定的に表示するため、新たにDBサーバにハードディスクを増設し、ハードディスク上の画像データを読み出し、WWWサーバを通じて影写本画像のデータを公開するシステムに改良した。これにより、影写本の画像データ表示の速度と安定性が増した。
(2)
「編年史料綱文データベース」のデータ構築について、現有の汎用機(AX7300)上へのデータ一括登録システムを改良し、年号、月日、編・冊・頁データをバッチ処理により登録するシステムとした。これにより、PC端末での索引付与作業におけるデータ入力時間が短縮され、データ構築環境が改良された。(3)
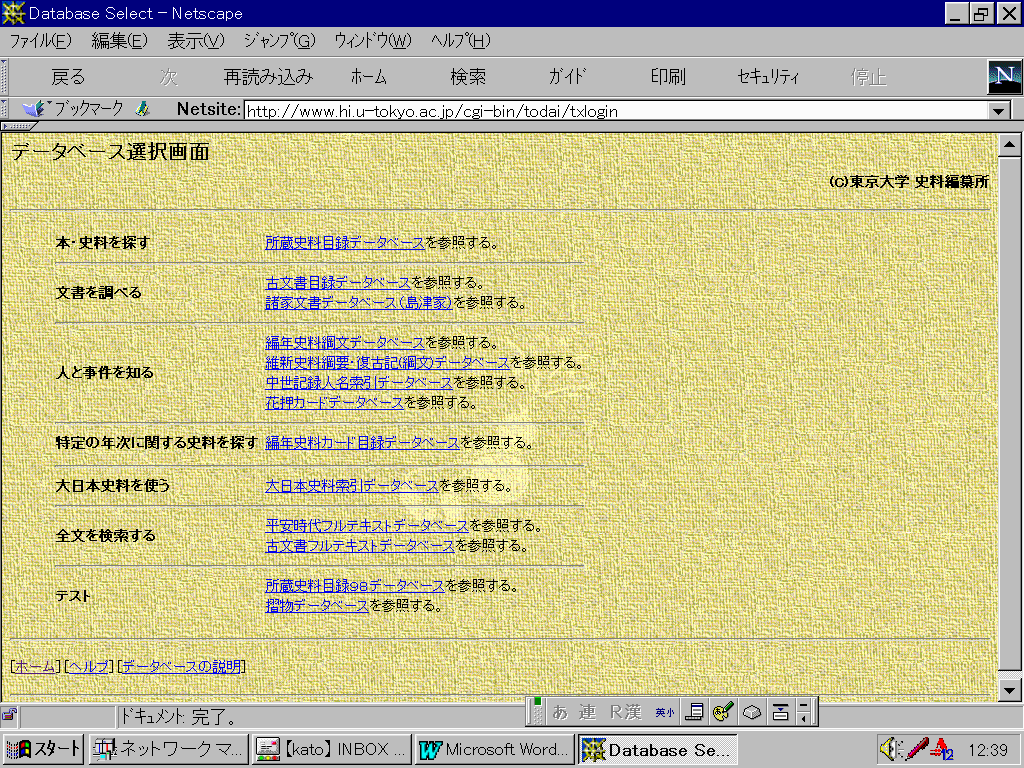
史料編纂所の出版物(『大日本史料』『大日本古文書』『大日本古記録』『大日本近世史料』など)のスキャニングによる画像データ作成とハードディスクへの格納事業に対応して、「編年史料綱文データベース」「大日本史料索引データベース」「平安時代フルテキストデータベース」「古文書フルテキストデータベース」の検索結果から、当該出版物の該当ページの画像データを表示するシステムを新たに開発した。以上のデータベース構築とその公開システムの開発により、史料編纂所のホームページ(/)を通じて、以下のデータベースが検索可能となった。
|
本・史料を探す 所蔵史料目録データベースを参照する。
文書を調べる 古文書目録データベースを参照する。諸家文書データベース(島津家)を参照する。
人と事件を知る 編年史料綱文データベースを参照する。維新史料綱要・復古記(綱文)データベースを参照する。 中世記録人名索引データベースを参照する。 花押カードデータベースを参照する。
特定の年次に関する史料を探す 編年史料カード目録データベースを参照する。
大日本史料を使う 大日本史料索引データベースを参照する。
全文を検索する 平安時代フルテキストデータベースを参照する。古文書フルテキストデータベースを参照する。 |
【
ホームページのデータベース選択画面】
2.1.1 史料編纂所歴史情報処理システム
http://www.hi.u-tokyo.ac.jpについて―本科学研究費で開発されたシステムと蓄積データの紹介を中心に―
横 山 伊 徳
本研究は、
東京大学史料編纂所の97年新システム導入にあたって、「オープン・イージー・ヴィジュアルなSHIPSデータベース」SHIPS for Internetを構築するため、様々な支援システムを開発・実験・運用することを目的としている。すなわち、
(1) WWW(World Wide Web)
を中心とする歴史情報システムのプロトタイプの構築(2) 研究者のデータ蓄積を相互に利用しあう環境の整備
(3) PC
やUNIXシステムでのフィルム・写真の画像処理方法が定着してきたので、画像データを蓄積・検索するシステムの開発という狙いを持つ。
これまで
15年間蓄積してきた各種データベースの構築環境を活かしながら、WWWを全面的に導入することにより、自ら質・量ともに増大する歴史情報の需要増大に応えることを目指す。
2. SHIPS for Internetの概要
SHIPS for Internet
は、旧SHIPSを継承発展させて、データ検索・画像処理などを分担する分散型ワークステイションを中心とするシステムであり、これらを相互に接続する高速のネットワーク100BASEはUTnet2に接続され、インターネットにより全世界とつながっている。
|
1.サーバシステム |
サーバシステムは、
WWWマルチメディアサーバ(NEC EWS4800/320PX)に、データベースサーバ(同EWS4800/460)とCD-ROMサーバを統合させ、加えて、メール/FTPサーバ(同EWS4800/320PX)からなる。とくに、現在所蔵史料の複製として16㎜マイクロ、全国・世界各国の史料収集には35㎜マイクロを用いており、この両者に対応した画像サーバのあり方を、本研究では重点的に工夫した。本研究により、インターネットに接続されている世界中のマシンから、史料編纂所のデータベースと画像が利用できるようになった。現在
SHIPS for Internetでは、公開利用可能なデータベースとしてつぎのようなものを挙げることができる。
|
データベース名 |
概要 |
本研究との関係 |
|
古文書目録 |
古代・中世の古文書の目録データベース。長期的には、全国の古代・中世文書の総合データベースに発展させるが、当面は本所所蔵の影写本所収古文書の目録データベースとして完成を目指す。 |
影写本画像サーバへのリンク |
|
大日本史料索引 |
『大日本史料』1・2・3・6・7編の近年刊行文の索引データベース。現在は人名のみ。 |
出版物画像サーバへのリンク |
|
中世記録人名索引 |
『満済准后日記』『吉続記』『経俊卿記』『花園天皇日記』『勘仲記』(継続中)人名索引データベース。 |
|
|
維新史料綱要・復古記(綱文) |
本所が編纂・所蔵する古代から明治維新期までの編年史料集の綱文(年月日順に配列したヘッドライン)のデータベース。『維新史料綱要』『大日本史料』『史料綜覧』が入力されている。文部省研究成果公開促進費の交付を受けて作成。 16㎜マイクロフィルムとの連動可能 |
出版物画像サーバへのリンク |
|
編年史料綱文 |
||
|
平安時代フルテキスト |
古文書(『平安遺文』)・ 『大日本古記録』(『貞信公記』『九暦』『御堂関白記』『小右記』『後二条師通記』)のフルテキスト検索 |
|
|
編年カード |
『大日本史料』編纂のためのカードシステム( 1編のみ) |
|
|
諸家文書目録(島津家) |
古文書目録データベースを史料群 (archives)対応型に改変したデータベース。現在、史料編纂所所蔵島津家文書のデータを収める。 16㎜マイクロフィルムとの連動可能 |
|
|
古文書フルテキスト |
平安時代フルテキストデータベースを基に、『大日本古文書』のフルテキストデータベースを構築するための拡張を施したもの |
システム開発 |
|
所蔵史料目録Hi-Cat2 |
図書部所蔵・管理する史料やマイクロフィルムの目録、『東京大学史料編纂所図書目録 第二部 和漢書写本編』(全 10冊)や『外務省引継書類』目録などの貴重書目録を収める。影写本画像サーバへのリンクを実現。 |
国際標準化構想 (ISAD)による史料群の階層的表現を可能にするシステム開発 |
このうち、所蔵史料目録データベース
Hi-Cat2は、従来ACOSやPCに別々に構築されてきた、図書部の各種データベースをPC上で統合した所蔵史料目録データベースを新たに組み立て直して、史料群の階層的表現を実現したものである(後掲別項参照)。画像サーバには、
WindowsNTマシン(Compaq DeskPro 2000)をコントローラとするCD-ROMチェンジャ(KODAK CD ADL 150)と、UNIXシステムへの大規模HDDという、2つのシステムを採用した。本科学研究費によって作成された画像のうち、『日本関係海外史料目録』(A4約6000ページ)の画像は前者に、影写本7200冊(35mmマイクロフィルムのべ約54万こま)の画像は後者に格納してある。そして、前者に格納される画像はすべて、後者に格納される画像は東寺百合文書など数種類の史料群について公開が実現している。(98年12月現在)|
2.中央システム |
中央システム(
NEC AX7300/150F)は演算速度12MIPSのCPUと記憶容量18GBをもち、史料編纂所が15年間開発してきたSHIPSデータベースシステムが稼動して、データの蓄積・加工が行われている。この
SHIPSデータベースの内訳は次の通り。|
データベース名 |
データベースの概要 |
|
古文書目録 |
史料編纂所所蔵影写本に収められた古文書目録 |
|
大日本史料索引 |
『大日本史料』の索引 |
|
大日本史料書名索引 |
『大日本史料』の引用書名の索引 |
|
中世記録人名索引 |
中世の記録史料の人名索引 |
|
維新史料綱要 |
『維新史料綱要』綱文検索 |
|
編年史料綱文 |
『大日本史料』綱文索引、維新と同システム |
|
古記録フルテキスト |
『大日本古記録』の全文検索 |
|
古文書フルテキスト |
古文書のフルテキスト |
|
編年カード |
『大日本史料』編纂のためのカードシステム |
|
(島津)史料目録 |
本所所蔵島津家文書の目録 |
本研究では、編年史料綱文の外部データインポートシステムの改良を行なった。この結果従来のシステムでは年月日データのインポートが不可能であったが、これが可能となり、修正過程での作業が効率化された。
|
3.パソコンネットワーク |
PCはいわゆるタワー型(NEC PC 9821V16)とノート型(NEC PC9821Nr150)で、100BASE-TXネットワークに対応している。本研究では、PCに特にインターネット関係および画像処理関係のアプリケーションを強化してインストールした。すなわち
WS_FTP Lite (windows
用FTPツール)View Director Pro (browser plug-in viewer)
何れも、96年時点では国内に相当品がなく、インターネット先進国アメリカから、ネットワークを通じて選定したものである。この二つのソフトは、歴史情報のインターネット公開およびその公開された情報の閲覧のために不可欠なものである。
3. SHIPS for Internetを支えるシステム
本研究の
狙いとするところは、Internet/Webへの対応のために導入されたされたハードウェアの環境=分散協調型システムを、如何に歴史学研究者にとって利用しやすいものとするか、という点にある。そこで次に、この研究に至る経緯、及び、研究の結果実現した機能の特性を以下に紹介したい。|
1.システムの中心として WWWサーバの採用 |
旧システム(
SHIPS 92)は、MML1として構築されてきた。これは当時の技術からすれば当然で、安定した中央システム故に、15年間大過なくデータを蓄積し続けることができた。しかし、同時に以下の問題も生じてきた。
(1)
中央システムは誰もがすぐに操作できるものではない上、各データベースの構築者が使いやすいと考えたシステムが統一なく存在するため、すべてのデータベースを自由に操作するということが非常に困難になったこと(2)
PCから中央システムのデータベースを操作、検索結果を印字出力して確認する、ということが原則であるため、手元で自由に確認することが困難であったこと(3)
自宅や他機関から中央システムの操作ができないこと(4)
画像サーバが特殊な端末を要求するため、PCから画像を閲覧することができないこと(5)
PCがWindowsとTCP/IPに移行したが、中央システムはこれらに環境に対応することが(貸借契約上)遅れたため、PC側でのSHIPS 操作にストレス(OSの切り替え)が蓄積したこと◆ ◆ ◆
95年から科学研究費重点領域研究『沖縄の歴史情報研究』(領域代表者、岩崎宏之(筑波大学))が開始されたのを踏まえ、本研究では、歴史研究におけるインターネット技術の応用について重点的に取り組むこと2が目論まれた。
SHIPS for Internetが前提としたWindowsとTCP/IP環境下では、
(1)
GUIが基本となるので、操作はほとんど画面をみるだけで了解できる。(2)
WWWの特性として、検索結果はPCへ転送されるので、PCでの検索結果確認ができる。(3)
インターネットに接続されてさえいれば、所内所外を問わず、どこでも検索可能である。(4)
.gifないし.jpg形式であれば、WWWブラウザで画像を表示することが可能である。(5)
PCのOSが標準でTCP/IPに対応している。という効果が期待できるので、検索システムの中心を
WWWへ移行した。
|
2. 全文検索システムの導入と画像リンクプログラムの開発 |
現在では、
WWWサーバによる検索システムは、検索エンジン及び各種データベースとの組み合わせで構築することは、ほとんど常識に属することとなっている。しかし、96年当時は、理論的には判っていても、現実にそのようなシステムは存在しなかった。つまりWWWサーバ対応のRDBは、(1)
いわゆる目録データベースのようなものは、比較的簡単に移行できるであろうが、全文データベースは、検索スピードの点で不安が残る。(2)
RDBのCGIプログラムがまだ開発端緒についたばかりで、完全作動が保証されず、自前の開発となることが予想される。という不安要素を抱えていた。
そこで
SHIPS for Internetでは、全文検索に特化したインターネット対応済みのパッケージ(平和情報センターFuture Happiness Light for Internet)を導入した。これにより実現した点は、以下の通りである。
WWWサーバとデータベースサーバの間のやりとりは技術的に解決した問題としてみなすことができる。
このパッケージ
では、データすべてをpreindexingするので、十分満足のいく検索スピードが出る。◆ ◆ ◆
周知のように、データベースサーバから
WWWサーバに送るさいに、HTMLによるマークアップによって、画面表示をコントロールすることができる。そこで各データベースでは、検索結果を見やすくするため、検索結果に対してダイナミックにプログラムを実行し、画面表示へのコントロールをおこなっている。本研究では、画像サーバへのリンクを二つのデータベースについて、二つのモードで実現した。すなわち、
|
データ蓄積のあり方 |
概要 |
|
|
古文書目録 |
架番号 |
画像サーバ上の該当ディレクトリを表示 |
|
画像番号 |
(実際は入力されていない) |
|
|
所蔵史料目録 |
架番号 |
同上 |
|
画像番号 |
イメージファイルが特定できるので、その画像を直接表示する |
である。つまり、架番号(出納番号)が入力されていれば、その番号の史料から作られた画像ファイルのリスト全体を表示し、そこから任意のファイルを選択・閲覧できるようにした。また、画像番号が入力されていれば、その画像を直接表示することもできるのである。
|
3. WWWがサポートする画像サーバの導入 |
本研究の
主目的は、Internetを通じて文書や史料の画像を共有可能にすることである。本研究ではまず、影写本の画像データをその研究素材とした。課題としては、
(1)
システムとして画像をどのようにサポートするか、(2)
画像データの具体的な作成プロセスをどう構築するか、ということにある3。
このシステムの構築には、現在全国各地で採訪された
35mmマイクロフィルムに収められた文書画像や900冊に及ぶ本所出版物をディジタル化していく作業のプロトタイプの構築という狙いもある。◆ ◆ ◆
画像をインターネットから供給することは、すでに実験的な段階ではなく、歴史学研究者が実用につかうツールとして機能することが要求されている。しかし、影写本約
7200冊画像コマ数54万コマをインターネットから利用するとなると、それだけの画像データを収めるstorageをどう実現するか、がまず問題である。95年秋の時点では、DVDなどの新メディアが開発されつつあったが、すぐに実用になるものは、
(1)HARD DISK
の増設(2)
光ディスク(3)CD-ROM
が考えられた。
(1)
は、システム的には考えるところが少なく、一番安定していてアクセススピードも早い方法である。しかし、画像ファイルの仕様が未確定の段階で、どのくらいの容量のディスクを用意すべきなのか、判断がつかずにいた。また、ディスクの値段がまだ大規模容量のものは非常に高く、コスト的に見合わなかった。(2)
は、SHIPS 92でも採用した。しかし、これは、光ディスクの仕様がメーカ独自であり、何より、TCP/IPへの対応が遅れており、インターネットで実用に供するには、ハード・ソフト共に開発ということが予想された。(3)CD-ROM
は、そこに収める画像ファイル形式がシステムに依存しない点では、(1)HARD DISKに類似し、データ保存の点では(3)光ディスクのもつ安定性、大容量を備えていた。また、CD-ROMの枚数を増やすことで、データ増加にも対応できた。また、CD-ROMチェンジャは、すでにTCP/IP対応を標準化しているか、もしくは、UNIXなどのオープンなOSに対応済みであった。以上から、研究当初の計画では、画像の格納には
SHIPS for Internetに導入されていたCD-ROMサーバ(KODAK CD ADL150)をもちいることにした。この機種は、3台のCD-ROMチェンジャを1台のWindowsNTマシンによってコントロール(ソフトはSmart CD)するもので、このNTにNFSを搭載することにより、見かけ上WWWサーバのハードディスクとして機能する。しかし、
97-98年の運用の結果、このCD-ROMサーバはいくつかの問題を抱えていることが判明した。NFS
マウントが安定しない。機械的な動作の時間(
CDのドライブへのロード時間)が、システム全体のレスポンスに比べて遅く、待たされるという印象がつよい。アクセスログの解析の結果、
CD-ROMサーバへのアクセスは、約4000件/週である。これは約3分に1件のアクセスが平均して発生したことを意味する。これは24時間平均であり、所員の利用が集中する10-17時では、恐らく1分に1件程度の頻度となっていると思われた。この頻度で(2)の状態であると、画像ファイルgetの要求が処理しきれないまま、次のアクセスを受け付けるということになり、(1)のNFSに待ち行列が溜まってしまった。結果、mountが外れるという事態が発生するようになったのである。そこで、
98年度に価格の急激に下落した大容量HDD(60GB)を導入し、利用頻度の高い影写本画像はこれに移動した。この結果、画像呼出にかかる時間は著しく減少し、システム全体としては安定運用が実現した。◆ ◆ ◆
一般には、インターネットにおける画像の取扱に関する制約は次の通りである。
(1)
ファイル容量上の制約 ファイルサイズは精々100KB前後が望ましい。(2)
ファイル形式 WWWブラウザで閲覧できるのは、.gifないし.jpg形式。しかし、影写本の画像を作成するにあたっては、これら制約を念頭に置きながら、まず次の二点を重視した。
(1)
画質の問題 単に閲覧できればよい、というレベルではなく、むしろ、歴史学、ないしは史料集編纂にとって必要なレベルの画質を供給したい。(2)
作成期間の問題 これまでの本所のデータベース作成作業は、10年単位で行なわれてきたが、画像データについて10年は長すぎる。できれば、一挙に実用システムとして立ち上げたい。そこで、次のような作成手順を踏むこととした。
(1) 20
年ほどまえに作成された35ミリマイクロフィルムをマザーとしてスキャンを行なう。(2)
マイクロスキャンはA3換算400dpiモノクロ2値とする。(3)
ファイル形式は、gifやjpegにこだわらず、必要ならばplug-inを利用する。(4) 28,800bps
の公衆回線モデムで接続したPPP接続を念頭に置き、100KB前後とする。以下、各項目について簡単に説明する。
(1)
は主として予算の節約のため。(2)
については実際の画質を比較検討した。この解像度ならはマイクロリーダプリンタ並みの画質となる。モノクロ2値にしたのは、A4レーザプリンタによる出力を前提にすると2値でよい、また、影写本自体が原本から文字部分を墨で写したものであり2値情報である、と判断したためである。(3)
gifやjpegはディスプレイ表示を念頭に置いた形式であるため、印刷したときの画質に不満が残る。そこで、高画質を確保するためにあえてgifやjpeg以外でも検討の対象に含めた。(4)
一般ユーザの環境からあまりにかけ離れた仕様での公開は、実質的な公開ではないと考えた。一画像を約一分半前後で入手できるサイズとなった(検索時間を除く)。結果、
plug-inを利用するということを前提に、tiff形式にG4圧縮をかけるという仕様でスキャンを行なうこととした。これは、現在35ミリマイクロスキャナでは標準で出力できるファイル形式である。また、2値画像として見た場合、gifやjpegと比較して高解像度の画像を提供することができる(後掲別項)。要するに現状では、マイクロスキャンの分野と、インターネットによる画像利用の分野とがあまり交流がなく、マイクロスキャンした画像を、WWWブラウザで見るという需要があまり想定されていない。その両者をつなぐのがplug-in Viewerである。本研究では、TMS Inc.のView Director Pro 2 +を採用した。◆ ◆ ◆
インターネット公開を前提に、
TIFF G4のファイル形式を採用すると、問題は、画質とファイルサイズのバランスである。マイクロフィルムの持っている情報をできるだけ多くディジタイズするには、解像度を上げ閾値を低めにとる。すると、画面は全体として暗くなり、G4圧縮は効かなず、ファイルは相当なサイズとなり、とてもインターネットで利用できるものではなくなる。しかし、
(1) 多くの場合、マイクロフィルムに写し込まれた情報は、例えば撮影台が写し込まれている場合のように、すべてが歴史学にとって必要な情報であるとは限らない。
(2) 紙質まで判読できるようなディジタル画像は時には必要だろうが、サイズがインターネットで流通する常識を逸脱するものでは、当初の狙い(インターネットによる共有)が果せない。
(3) 更に、経験的には、このような高感度の画像はスキャンニングのタイミングをとることが難しいらしく、一部に流れた画像が発生する。この画像は、イメージの輪郭がぼけて
G4圧縮に向かず、必要以上にファイルを大きくする。以上のような経験を積んで、
(1)
トリミングを実施する(2)
影写本の場合、地が白く一色で表示されるような閾値に調整する(3) (1)
、(2)によるスキャンエラーを減少させるという、スキャンニングの「コツ」のようなものを体得できた。
◆ ◆ ◆
既に述べたように現在影写本画像サーバは、
WWWサーバの外付けディスクとして機能している。この画像サーバに収められた画像一ファイルは、影写本一冊毎に一フォルダにまとめられ、現在約
7200の影写本画像フォルダが存在する。そして各影写本画像フォルダは、撮影順に00000001から00007200までの一意の番号が付与されている。各画像フォルダには、やはり撮影順に影写本の見開き画像が00000001.tifから順番に収められている。つまり、影写本の冊→丁という構造は、フォルダ→ファイルという関係に射影変換されているのである。◆ ◆ ◆
以上のシステムを古文書目録データベースに組み込んで、現在進んでいる影写本の目録作りによりインターネット上で巨大な『日本古文書影印集成』を作成することが可能となる。しかし実際には、影写本すべてについてファイル名を特定することは、とりもなおさず、古文書目録データベースが完成することであり、
10年単位の時間がかかるであろう。そこで現在は、影写本タイトルと画像とのリンクを実現した。すなわち、古文書目録データベースから該当する古文書画像データファイルが収められている影写本フォルダを指示する。この方法なら、約
7200のフォルダへのリンクを実現すればよいことになり、比較的短期間に実用システムとなる。検索結果が直ちに画像表示ということにはならないが、フォルダ内のファイル指定はユーザ自身がフォルダ内を検索・閲覧することでユーザ側の操作に委ねる4という手順を採用した。|
4. PCサーバによるHi-CAT 2の開発 |
PCサーバ(NEC Express5800/140 133MHz*2, 10GB)のシステムについては、多くを語る必要はない。敢えて付言すれば、この導入によって実現したファイル共有は、編纂者がPCに依存した編纂を行なえば行なうほど、必要とされる。なぜなら、多くの場合編纂は共同作業であり、作業の結果をファイルとする場合、共同作業者が共通してファイルを利用できることが不可欠だからである。実際、導入後共有フォルダが相当増加している。システム運用開始1年余で共有フォルダに用意した4GBは既にして飽和状態となり、現在8GBに増設している。
PCサーバ導入の狙いのもう一つは、デバイス共有にある。辞書サーバの設定や高速・カラーレーザプリンタのネットワーク共有に使われている。
◆ ◆ ◆
従来研究部を中心に構築されてきた研究用の
SHIPSデータベース(ACOS)とは別に、図書部がPCを利用して、図書管理のためのさまざまなデータベースを作成してきた。今回、このデータベースを統合し、PC上に一つの大きな図書部データベースを作成した(所蔵史料目録データベース)。本研究では、このデータベースに本格的な改良を加え、PCサーバによるデータベース共有システムのプロトタイプ(Hi-CAT 2)開発に取り組んだ(後掲別稿)。具体的には、
(1) PC
サーバにデータベースソフトSQLサーバを導入し、5台のPCにクライアントを設定する。(2)
既にAccess97で開発してあった新しい所蔵史料目録の構造をSQLサーバに反映する。クライアントPCに
Access97によるフロントエンド画面を設計する。(3)
外注業者への発注データ(『東京大学史料編纂所図書目録 第二部 和漢書写本編』全10冊)および既存の所蔵史料目録PC版データを一括処理してインポートするプログラムを開発する。(4)
このデータ構造にあわせて、WWWの検索データベースも改良を加える。というものである。この開発によって、所蔵史料目録データベースは、史料編纂所が所蔵する非刊行物系のすべての図書・史料を取り扱えることとなった。
(注)
1. マイクロチップの載ったPCと中央システムとの連携、
Micro- Main-Link2. 私も本所所蔵『琉球外国関係文書』のホームページ
(/ personal/yokoyama/okigindx.htm)を開設しました。3. 影写本画像データの作成については、並木美太郎氏(東京農工大、新システム技術評価委員、重点領域研究『沖縄の歴史情報研究』メンバー)柴山守氏(大阪市立大、同上)坂口瑛氏(筑波大、同上)には、さまざまなご教示を得ている。
4. 文字どおり、
Browse(拾い読み)することになる。このためにも、画像ファイルは小さくして、トラフィックにかかる時間を短くする必要が生じる。勿論、丁数順とファイル順とは一致している(はず)なので、古文書目録データベースの検索結果から一応の見当はつく。この考え方はISADをはじめとする公文書検索システムの考え方と共通している。この考え方の、従来の一点目録主義に対する優位性は、近藤成一「史料編纂所と電算機」『歴史評論』(578、1998)72頁参照。
〔附記〕本稿は、「1997年2月稼働史料編纂所歴史情報処理システム」(『東京大学史料編纂所報』第32号、1998年)及び「東京大学史料編纂所データベースSHIPS for Internetについて」(『沖縄の歴史情報』No.7、1997年)に加筆訂正したものである。
2.1.2 SHIPS for Internetにおける画像提供について
―影写本データベースと錦絵データベースにおける画像ファイル―
横 山 伊 徳
1. それはバブルのころ始まった
ある古書展で「絵のあるものは、最低
30万円です」という掲示をみて驚いたのは、バブルの頃であったかと記憶する。明らかに世の中の関心が「目で見てわかる」ものへ動いていることを実感した。文字とコマンドの世界だったコンピュータ界にも「目で見てわかる」動きは押し寄せてきた。インターネットも、メニュー構成のgopherから「目で見てわかる」Mosaicへと急速に変化をとげていた。このような変化をふまえ、研究メンバーである加藤友康・近藤成一・鶴田啓・山口英男の各氏と共に、コンピュータで画像を扱うという素人のにわか勉強が始まった。このときの勉強が、/配下の画像データを支えている。
2. 画像はバブル
日本の感覚では、現物をスキャナにかけるのは論外とされて、現物史料を直接ディジタイズすることは困難である。しかし一点ごとに
A4サイズの焼付を作り、それをスキャンするのではコストと手間がかかり無駄も多い。幸いにも、撮影フィルムをスキャンする手法が実用化されてきた。現物史料を撮影し、フィルムをスキャンしてデータを作成するのを原則とした。2.1 Photo CD(PCD)ファイル
PCDファイルはKodakが開発した、フィルムスキャン=CD-ROM焼き付けの一連のシステムで使われるファイルで、1/16Baseのファイルから16Baseまで5種類のサイズのファイルが一度に作成できる。作成に際しては、DPEと同じく写真店へ発注すればよい。CD-ROM1枚に100枚まで画像を収められ、また、多くの画像ソフトがPCDファイルに対応しているので、現在の標準的なPCでは扱いやすい画像形式である。現在はディジタルカメラが隆盛だが、画像の質がよいこととフィルムというバックアップが残るというPCDファイルの利点は失われてはいない。コストの面でも、ファイル保存、変換などトータルに考慮した場合には、十分な利点がある。PCDファイルには、もう一つ上のPro-PCDの規格もあるが、こちらの64Baseは現在のPCにとってはオーバースペックである。
2.2 TIFFファイル
TIFFファイルはAdobeが開発したビットマップファイルである。ファイル自体に様々な情報を組み込めるのが特徴で、複数画像をページをめくるような形式にすることもできる。現在ではドキュメント系の画像ファイルとして広く使われている。フィルムからこのファイルを作成するには、富士フィルムMS-1600などのディジタルマイクロリーダが必要となり、実際には専門業者に発注しなければならない。本研究で、影写本マイクロフィルムのディジタイズを行なったが、そのファイル作成にはこの形式を採用した。
フィルム・ディジタイズにおいて特に留意すべきは、次の
3点である。2.2.1 フィルムの状態チェック
多くの場合、ディジタイズを前提として撮影・保管されていない。したがって、フィルムがディジタイズに適した状態にあるかどうかをチェックする必要がある。たとえば、フィルムをセロテープで接合している場合や、引き伸しの際にマーカーで印を付けた場合などがこれに当たる。
2.2.2 画質のチェック
撮影時の露出のオーバー・アンダーなどもチェックしたい。幸い影写本マイクロフィルムの場合、本所の技術官が撮影したものなので、撮影時の質が比較的安定しており、フィルムスキャンもスムーズであった。一部であるが、フィルムスキャナにおいて、フィルムの回転とスキャナの移動とがあわず画像が流れる例やモアレを発生する例があり、チェックは不可欠である。
2.2.3 トリミング
撮影は通常、万一のことを考えてターゲットである被写体を十分収めるようにしてある。そのため、フレーム一杯にスキャンすると不必要な部分も多くなり、かつその部分の情報量が大きいということがしばしばある。多少手間がかかっても、トリミングを指定した方がよい画像が得られよう。
2.3 バブルな画像
こうして作成した画像ファイルは、予想外に大きく
PC程度の力では扱いにくい。たとえば、4BaseのPCDファイルは6MB程度となり、A3/400dpiのTiffファイルは2値であっても1.5MBになってしまう。しかも、ネットワークの事情も現実的には無視できない要素である。インターネットが混雑してなかなかつながらない、という事態が生じるようになった。専門家の話では、高速道路と同じで、太い回線を作れば通行量が増えるので渋滞は変わらない、という。となると、あまり大きなファイルを作るのはネットワーク環境を破壊する行為である。100KB程度に押さえる、というのが至上命題となった。
3. 圧縮について(TIFF G4ファイルとJPEGファイル)
このファイルサイズとネットワーク事情の間の矛盾を解決する手段が、ファイル圧縮である。つまり、画像ファイルを圧縮して小さくしてからネットワークを流通させ、クライアント側で圧縮を解いて、もとの画像に戻すという仕組みにするのである。この圧縮方式も、先の画像ファイルに対応して二種類ある。
3.1 JEPG形式
JEPGファイルについては周知であろうが、インターネットの標準ファイルであるというのが最大の特徴である。インターネットのフルカラー画像はほとんどこの形式が採用されている。また、ディジタルカメラなどもこの形式を採用するものが多く、実質的にPCの世界ではもっとも広く用いられている画像圧縮形式であると考えられる。
錦絵はカラー画像でないと意味がないので、とりうる方法は
JPEGしかない(注)。PCDファイルに対してJPEGファイルに変換してJEPG圧縮をかけるのは、標準的な画像ソフトで可能となっている。商業用ポスター作製にも用いられるという35mmカラーフィルムをスキャンし、Paint Shop Pro(本所ではVer.3.2を採用)でJPEGファイルを生成する。100KBでも、画像の大きさ(画素数)が小さければ、かなりの高画質は得られる。しかし、絵が小さいと錦絵では文字が読めない。結局、文字が読める大きさを確保して、圧縮率を高めた。勿論高圧縮すると画質が劣化するので、高画質印刷には向かない。(注)最近Flash-Pixという画像形式がKodakにより開発されて、注目を浴びている。これは、PCDと同じく同一の画像に対してサイズ の異なる複数の画像を用意する。Flash-Pixの特徴は、これら複数の画像がすべて64*64pixelの小画像(タイル)に分割されていることである。同一サイズでは、このタイルのみを繰り返し読みだせばよいので、ファイル全体を読むのにくらべて処理が早く済む。また、異なるサイズで関係するタイルを読み出していけば、拡大縮小が実現される。
このファイルの現状でのデメリットは、全体をある大きさで見るときには、やはりかなり大きなファイルとなってしまうこと。また、現状では、タイル同士の関係付けにhttpdでは対応していないので、専用のサーバが必要になること、また、当然の事ながらブラウザへも専用のプラグインが必要となること、などが考えられる。しかし、サムネイルを別に作らなくてよい点だけみても、本格的なカラー画像サーバを構築する場合、かなりの工程を省略できるので、今後はインターネットでも急速に普及が進むであろう。
なお、
Flash-Pixをブラウザで閲覧するためのプラグインは、http://www.livepicture.co.jp/download/index.html
で入手できる。3.2 CCITT Group4形式
これは、ファックスなどの画像転送の際に用いられていた画像圧縮の形式の流れをくむもので、
2値化された画像ファイルに対しては、非常に高い圧縮率を実現している。しかも、JPEG圧縮が画質を低下させるのに対して、圧縮前の画質を損なうことがなく、印刷時にも美しい画像をえることができる。しかし、インターネットの標準ファイルではないので、閲覧するためには様々な別の仕掛けが必要になる。そこで、ブラウザにTiff G4圧縮のファイルを扱えるプラグインTMS Inc. View Director Pro (http://www.tmsinc.com/internet/ product/) を組み込んで、ブラウザから閲覧できるようにした。http://softpark.cplaza.or.jp/lib/mm.html
には、この種のプラグインソフトが多数リンクされている。本圧縮で留意すべきは、画像の質によって圧縮率が変動することである。白黒がはっきりしている画像では相当の圧縮が期待できるが、影やかすれが多い画像では、あまり圧縮が効かないのである。従って、影写本画像のように、全部で
50万コマ以上のファイルを作成する場合、その格納ディスク容量をどの程度にすればよいか、という試算が困難であった。本研究では、CD-ROMサーバという300GBという余裕の容量を確保できたので、実際的な困難は発生しなかったが、HDDなどへの格納の場合は、その見積もりは難しいと考えられる。本所の最大の画像資源は、マイクロフィルムである。もともとモノクロだから、上手に2値化処理すれば
TIFF G4形式ファイルとして上記要件を満たす。影写本7200冊のマイクロフィルムの画像約53万コマを60GB程度に収めることができた。この画像は、すべて所蔵史料目録データベースにリンクされており、同データベースを検索した結果、影写本がヒットすれば、その画像を閲覧することができるようになった。また、試験的に、『日本関係海外史料マイクロフィルム目録』(全
15冊中、品切分14冊)をスキャナにより、やはりTIFF G4形式にディジタイズした。全体では約6000ページ程になるが、ファイルサイズは250MB程度であり、CD-ROM1枚に収まることが確認された。この画像は、/personal/ yokoyama/hensan/microfilm.htmからすべて利用できる。
4. 結論
インターネットで提供すべき歴史資料の画像ファイル形式について、以上の取り組みから、本研究での成果を元に、一応の指針をまとめておきたい。
4.1 フィルム撮影を残すべきである
史料を直接スキャンできない、という制約からだけではなく、写真技術のノウハウはディジタル技術にも十分対応でき、また、ディジタル技術の変化の早さに比して(あくまでも比較の問題)フィルムは安定的であるので、(ある程度の規模の)画像データベースを構築する場合は)当面フィルム撮影は不可欠のように思われる。
4.2 画像の需要を見極めるべきである
なぜ画像ディジタル化が必要なのか?保存か、利用(レタッチ)か、共有か、によって作成すべき画像ファイルを選択しなければならない。
現在の技術では、すべての用途に適した
multi-purposeファイルはない。本研究では、保存はあくまで現物で行なうべきと考え、史料閲覧の時間と距離の制約を減らすことに力点を置き、共有ということを第一に指向した。4.2.1 モノクロ画像でよい場合は、TIFF G4を採用する
Windows95(osr 2.*)
ならば、TIFF G4の画像を見ることは標準で可能となった。4.2.2 カラー画像が必要な場合は、JEPGを採用する
ただし、カラー画像の場合は、技術的な進歩が激しいので、サーバ技術の進歩により別のファイルに移行することも念頭に置くべきである。
〔附記〕本稿は、「錦絵ギャラリーと錦絵データベース」(『画像史料解センター通信』第
2号、1998年)に加筆訂正したものである。
2.1.4 所蔵史料目録データベースver.2(Hi-CAT)の開発
横 山 伊 徳
1. 開発の動機
本稿は、本研究において開発した『所蔵史料目録データベース』
ver.2(以下Hi-CAT)について、開発経緯と開発理念、開発システムの詳細を述べることを目的とする。本システム開発及び本稿執筆において、本所図書部内村奈緒美・柿沼徹両氏には多くのご協力をいただいた。
1.1. 97年2月以前
1.1.1. 情報の管理と物の管理
本所が電算化に取り組み始めて既に
15年経過する。その間、SHIPSとして開発されてきた多くのデータベースを見れば明らかなように、歴史「情報」の管理・整理のためのデータベースが主要なデータベースを構成してきた。全文データベースしかり、綱文データベースしかり、索引データベースしかり、である1。これは、編纂者として歴史「情報」をpublishする職務のしからしめるところである、といえる。ところが、歴史「情報」を生み出すところの、史料そのもの、写本、マイクロフィルム、といった物の管理・整理のためのデータベースというのは、
SHIPSの主要なデータベースとして位置付いてこなかった。一方、93年2月に電算機レンタルが開始される以前から、この物の管理・整理を担当していた図書部では、ACOS上のマイクロフィルム管理データベースや、LANFILE/N5200、さらに93年2月以降導入された『桐』を使って、データを蓄積してきていた2。1.1.2. 統合化
詳しい聞き取りを行なったわけではないが、
93年以降、PCによるデータベース入力を行なっていた図書部では、各特殊蒐書や各種形状毎に異なっていたデータベースを統合化することを指向するようになった。この背景には、『桐』の上に構築されてきた写真帳データベースが図書部史料掛の中核的データベースとしてデータ蓄積を大きくしてきたことがあると思われる。『桐』はそれらのデータベースを統合するだけの能力を備えたソフトであった。こうして、ローカル版所蔵史料目録データベースver.1の原型ができあがっていった。これは、SHIPSが97年システム更新に当たって、本格的に物の管理に踏み込んでいく、大きな原動力となった。そして、99年3月まで稼働を予定しているWWW版所蔵史料目録データベースver.1は、このローカル版を組み替えて作成された。
1.2. 97年2月以後
この統合化への動きは、
97年2月の電算機更新におけるN5200シリーズの不採用、ACOSシステム上のマイクロフィルム管理データベースの閉鎖、などによっていよいよ本格化した。しかし、皮肉なことに『桐』と新しいOSであるWindows95の相性が非常に悪く、この更新では『桐』ではなく、『ACCESS』が採用されることとなった。図書部における所蔵史料目録データベースver.1は、(『ACCESS』採用を決めた張本人が言うのも気が引けるが)先の見えない『桐』の上に構築される不安を抱えることになった。Hi-CATへの動機は、まずこの点にある。1.2.1. 『東京大学史料編纂所図書目録 和漢書写本編』(全10冊)の入力
一方、図書部データベースの統合化の動きを踏まえ、本研究ではその利用度を一挙に高めるべく、標記の目録を全冊外注入力することとした。しかし、ここにも問題が発生した。所蔵史料目録データベース
ver.1のフォーマットにあわせて入力すると、データの繰り返し入力が増えるので、目録ベタ入力の1.5倍程度の費用3がかかると見積もられたのである。Hi-CATへの移行の、第二の理由である。1.2.2. WWWデータベースへのデータ移行の問題
更に、『桐』そのものが抱えている問題も深刻であった。『桐』はデータベース利用の困難を少なくするため、ユーザに対して厳格なリレーショナルデータベースの作法を要求しない。そのため、プライマリー(主)キー(レコードの一意性を保証するフィールド)なしでもデータベース構築が可能となっている。しかし、
WWW上のデータベースは厳格にこの主キーを要求する。したがって、『桐』上の統合データベースを構成するいくつかのフィールドの組み合わせにより、主キーを再構成するしかない。普通の判断では架・番・号が主キーとなるが、本所の場合、架・番・号が同一で別レコードという場合が少なからずある(合綴の場合4)。従って、統合データベースから
WWWへデータを受け渡す際、いくつかのトリッキーな処理が発生し、そのため、この過程を完全自動化できないでいた。これが第三の理由である。以上から、主キーを備えた(それなりに厳格な)
Windows版RDBをベースに、フィールド構成を考え直したヴァージョンアップが目指されることとなったのである。
2. 国際標準記録史料記述ISAD(G)
では、どのような形でデータベースのヴァージョンアップを目指すべきか。私の念頭にあったのは、国際標準記録史料記述
ISAD(G)である。この詳細は他の文献に譲る6が、90年代初頭から国際的に活発になってきた、文書目録の形式を標準化しようという文書館学の一つの達成と考えることができる。2.1. 階層構造論
ISAD(G)は、多元レベルでの記述を根幹に据えている。すなわち
2.1「(記録史料の)記述は、部分と全体とを関連づけて、もっとも広い範囲(
fonds)からより狭い範囲へ、という順序で記載」し、2.4「上位レベルでの記述で既に与えられた情報を、下位レベルで繰り返さない」
と規定している。そして、このレベルとして、全体
fondsから個別Itemまで複数のレベルを設定する、というものである。私の理解するところによれば、これは、物理的な最小単位である冊および論理的な最小単位である一件・一点を記述してきた従来の目録に対して、冊と件の関係だけではなく、冊と冊の関係、あるいは、全体と冊との関係を明示することを求めているものである。
2.2. ISAD(G)によるデータベースの構造モデル
では、以上のような多元レベルの記述をデータベース上で実現するには、どのようなテーブルを考えれば良いであろうか?
2.2.1. フラットモデル
このモデルは、
ACOS上の島津家文書目録で試みられた方法である。各レベルの記述内容は同一のテーブルの中に格納しつつ、一方で記述のレベルを示すコードのフィールドを設定し、このコードを階層的に管理することにより、各レコードを階層的に表現しようというものである6。2.2.2. リレーションモデル
このモデルは、各レベルのデータを格納するテーブルを、書目
(series)・冊次(file)・詳細(item)等と物理的に分けてしまい、この各テーブルの間をリレーションで結ぶというものである。結論から言えば、
Hi-CATでは、このリレーションモデルを採用した。理由は、以下の通りである。(1)
『ACCESS』がリレーションシップを非常に簡単実現するので、私のような素人でも多少勉強した程度で、リレーションモデルのプロトタイプを構築できる。(2)
リレーションモデルとしたことで、書目レベルの記述=入力は、冊次以下で繰り返す必要がなくなり、結果として入力文字数が減り、コストダウンとなる(はずであった)7。(3)
架番号とは別に、『ACCESS』がソフトウェア的に主キーを発生させてくれるので、合綴本の処理のような主キーに関わる処理が不要となり、結果、WWWサーバへのデータ移行を自動化できる。(4)
すべてのレコードに一意のコードが付いたので、その一意のコードへ画像サーバや解題データとのリンクを持たせれば良いことになった。
3. 運用システム開発
基本となるデータベースのモデルが決定したので、実際に史料掛でこのデータベースを運用するシステム全体を設計・開発することとなった。
3.1.1. システム運用の基本方針
図書部受入・整理業務フローと新規データ形成
まず、非刊本系史料の受入・整理業務について業務の流れについて、以下の通り整理しておく。
|
受入・検収 |
書誌記述 |
登録 |
装備・配架 |
統計 |
|
( 登録番号の発生) |
データ入力 |
三連符図書原簿・属紙作成 閲覧・事務用カード作成 事務用リスト作成 etc. |
年度ごとに種類別受入数集計 |
これを見れば明らかなように、非刊本を取り扱う史料掛では、受入の段階から、様々な形でコンピュータを応用しており、これらを全体として支えるシステムが必要とされた。新規受入された史料は、特別なことがない限り、
Hi-CATに格納されることになる。3.1.2. 外部データの受入
一方で既に所蔵する史料のデータについては、上記のフローとは関係なく、データ作成が行なわれてきたし、現在も進行中である。それゆえ、それらをインポートする機能を備えることが不可欠である。
また、現存する所蔵史料目録データベース
ver.1のデータを一括してHi-CATへコンバートする機能が必要である。3.1.2.1. 図書部作成データ
Hi-CAT
に入力されるべき、図書部作成の一括データの主要なものは以下の通り。|
史料目録データ |
所蔵史料目録Dbver.1のデータをHi-CATへコンバートする |
史料掛 |
|
寄贈フィルム目録データ |
既存データをコンバートするとともに、Hi-CATへも入力。 |
運用掛 |
3.1.2.2. 研究部作成データ
Hi-CATには、研究部が研究費で入力する本所所蔵史料の冊目録・一点目録、解題、画像サーバリンク情報まで含めてすべてインポート可能とする。これらの主要なものは、以下の通り。
|
『東京大学史料編纂所図書目録 和漢書写本編』 |
本科学研究費で作成。研究部作成データのインポート方法開発の意味も含める |
|
日本史史料書誌統合データベース |
98 年度研究成果公開促進費による作成。目録未入力非刊行史料をなくしていく。 |
|
画像史料解析センター作成データ |
本所所蔵肖像画模本・本所所蔵錦絵など |
|
貴重書0071架画像データ |
特定研究経費 |
|
入来院文書データ |
目録データ・本文(原文・英訳)および画像データ。同上 |
3.1.3. WWW版Hi-CATについて
ローカル版所蔵史料目録データベースのヴァージョンアップに合わせて、
WWW版Hi-CATの設計にも取り組むが、ポイントは二つある。(1)
図書部から要望の強い、更新間隔の短縮(現在は半年に1回)を実現するため、ローカル版のデータをWWW版へ移行する方法を自動化する。(2)ISAD(G)
にできるだけ準拠した目録検索結果のWWW表示を実現することである。つまり、検索者に対して、書目(series)・冊次(file)・詳細(item)という構造を意識させる検索インターフェイスの一つのプロトタイプ8を提示することである。3.2. NT server システムの概容
ローカルなサーバとして
NT3.51マシンがあり、クライアントにはACCESSが搭載されているというSHIPS 97の現状を踏まえて、以下のように構想する。(1)
サーバにSQLサーバを備え、クライアント側にはACCESSをフロントエンドとするサーバ=クライアント型のローカル版Hi-CATを構築する。(2)
ローカルサーバとWWWサーバの間は、リアルタイムの更新とはせず、データのFTP転送によって行なう。
|
所蔵史料目録データベース ver.1 |
コンバート → |
NT server 上のSQLサーバ(Hi-CAT/local) |
FTP → |
WWW サーバ(Hi-CAT/Web) |
|
↑ ↓ |
||||
|
外部データの作成 (.xls/.csv) |
File → |
ACCESS をフロントエンドとするクライアントPC |
||
|
↓ |
||||
|
各種帳票出力 |
3.3. WWW(Hi-CAT/Web)について
Hi-CAT/Web のインターフェイスの設計に当たっては、既に述べたように
(1)
階層構造を踏まえた検索とキーワードによる主題検索との二つの検索モードを用意する(2)
史料の階層構造が理解できるインターフェイスとすることとした。画像サーバや解題データとのリンクは、従来通り
(ver.1と同じ)の機能を実現する。3.3.1. 『全表示』と『限定表示』の二つのモードを用意
検索結果一覧画面でラジオボタンにより{ 全表示|限定表示 }を選択させる方式にした。デフォルトは、{全表示}とする。これにより、たとえば、ある検索の結果必要な史料が『続通信全覧』(編年之部)に収められていることが判ったとすると、『続通信全覧』(編年之部)の構成(「米国往復書翰」「蘭国往復書翰」……)を確認しながら必要な史料にたどり着いていく検索と、いきなり『続通信全覧』(編年之部)「孛国往復書翰」之一を表示する検索と二通り用意した。
3.3.2. 検索結果の階層表示
検索結果の表示を3段階に分ける。すなわち第一段階では 《書目テーブルのデータ》+《冊テーブルのデータ》、第二段階では 《細目テーブルのデータの一覧表示》、第三段階では《細目テーブルの一件データの詳細》を表示する。
4. 結論
Hi-CATが従来の検索システムと異なる特徴を持つとすれば、それは、
(1)
データの発生源=史料登録時からデータを管理するシステムであること(2)
データを階層的に蓄積していくことが可能なシステムであること(3)ISAD(G)
の主唱する階層構造論9をシステムレベルで意識したシステムであることなどが挙げられる。このシステムにより、本所が所蔵するほとんどすべての史料の電子目録化と画像サーバへのリンクが実現するはずである。
(注)
1.
古文書目録データベースは、物の管理と情報の管理の中間的な位置にあると考えられる。しかし私見では、同データベースには、その中間性故に性格が曖昧になっていると思われる。2. 史料掛で作成されている①史料目録②マイクロ,シートフィルム目録、運用掛で作成されている③寄贈フィルム目録など。
3. 『桐』で管理されていた統合データベースは、書名テーブルと史料名テーブルという二つのテーブルを持っていた。書名は架・番・号の号で特定される一冊を記述するテーブルである。このような構造をもつと、たとえば、『寛政重修諸家譜』
800冊の写真帳に対して、タイトルや所蔵者など全部が同じデータを800回入力しなければならなくなる。その結果、キータッチ数が増え、300万円のものが450万円となってしまう概算が成り立つ。4. 歴史的な経緯は不明であるが、本所の図書目録(ないしその元になる図書カード)では、
AとBとの二つの史料が合綴されて一冊となっている場合、あたかも史料が二冊存在するかのように記述される。これを2レコードととしてデータベースに組み込むと、物理的には一冊なので架番号は同一となり、架番号は主キー(uniquenessを示すフィールド)たり得ないので、エラーとなる。普通の歴史資料の取り扱いだと、タイトルでは「A・B」として一冊=一レコードとして記述するように思われる。このような合綴本処理には、Bを検索する都合上そのような扱いとした方が検索しやすい、AとBが全く別物で目録で分類を分けるときに扱いやすい、などの理由があると思われる。そうした利点も、たとえば、参照カード(「~を見よ」というカード)を立てることで代替可能であろうと考えられるが、本所の図書カードはそのようになっていない。5. 森本祥子訳「国際標準記録史料記述:一般原則」『記録と史料』(
vol. 6, 1995)6. たとえば、島津家文書の白木箱一の三本目の巻子の中の、源頼朝書状を示すのに、
SHIMAZU-SHIRAKI01-KANS003-9999
と表現するコードを用いたのである。
7. ただし、入力業者が、アクセスのようなリレーションを維持できるデータベースで入力しないと、様々なトラブルを生むことになる。
8. イギリス公記録局
(PRO)では、AD2001Programmeと称し、Online Catalogue Projectが進行中である。これは、「PROの考えは、21世紀には、PROの利用者はそのサービスや記録の利用に際して電子的な手段を用いるようになるだろうというものである。私たちのArchives Direct 2001 Programmeは、このための基礎を築くことを目的とし、31 December 2001までに、 PROは、その利用者に以下のサービスを提供できることとなろう。(1)
世界中どこにあっても24時間遠隔地利用者に提供されるWWW参考・問い合わせサービス(2)
検索手段の記録記述へのオンラインアクセス、これは世界中から利用可能で、文書の構造を踏まえた検索もキーワードによる主題検索も可能である(3)
インターネットによる文書閲覧請求……」( ここで述べられているように、単にキーワード主題検索だけでなく、文書の構造(それがfonds→itemであることは既に述べたとおり)を踏まえて検索するという機能が必要である、というのがPROの考え方である。9. ISAD(G)には、もう一つ記述要素論が含まれているが、これについては、今回は検討しない。ただ、私見を述べれば、
ISAD(G)の記述要素論には、RDB型のデータベース構造論が色濃く反映していると思われる。しかし、現実の検索システムは、RDB型の検索システムから徐々に離れつつあるのではなかろうか?
2.1.5 Computer Aided Research in Medieval Japanese History:
Focusing on Full-text Database1
Hotate Michihisa(保 立 道 久)
The first problem we encounter when discussing the use of computers for historical and archival studies in Europe and Asia is the quantity of historical documents we have in each of our countries. Moreover, in order to get an idea of how many documents there actually are, we already need a computer. So this thesis leads to a kind of tautology, but I think that in the future we will know the amount of written materials by the number of bites that they require.
Consequently, since we do not yet know the exact number of written documents, I can only give approximate numbers. For instance, the Shosôin-monjo
「正倉院文書」, a collection of 8th century documents, consist of about 10,000 documents. And the Heian-ibun, which was compiled by TAKEUCHI Rizô, consists of 5.500 9th century to 12th century documents. The Kamakura-ibun, also compiled by TAKEUCHI Rizô and includes documents from the end of 12th century to the middle of the 14th century, consists of 33,000 documents. And, from the end of the Kamakura-period to the beginning of the Edo-period, we have no measure to count the numbers of documents, but it seems there are over 200,000. Furthermore we have diaries (nikki 日記) by aristocrats, various types of literature (monogatari物語、Waka和歌etc.), classics (tenseki典籍) and numerous religious documents(shôgyô聖教). In any case, as far as the archives from the 8th century to the 12th century are concerned, Japan has the largest extant collection, comparing to any other country, especially in Asia.Of course these are no concrete statistics, mainly because there are still enormous numbers of medieval documents that are not yet published neither catalogued. Most of them are in the stacks of big Buddhist temples and sometimes they are written on the reverse pages of sutras. Furthermore, as you know, manuscripts written with a brush (môhitsu
毛筆) on Japanese thin paper are difficult to read, especially when they are written in various and arbitrary script forms.Consequently, the compilation of Japanese medieval archives is hard labour which will still take a long time. For instance, the compilation of the Todaiji-monjo, the most famous archives of Japanese ancient and medieval history, will be, under the present conditions, scarcely finished around 2200 AD. Thus, the reason why the working group of the Historiographical Institute decided to make databases of historical documents, is because we wanted to accelerate and streamline the compilation of computarized archives.
In case you would like to have a look at our work, the easiest thing to do is to check our homepage with a computer that can read and write Japanese and is equipped with a Japanese operating system. Since not everyone of you possesses such a computer, I will explain the outline of our project.
1. Pictorial Database (Gazoshiryo database
「画像史料データベース」).Two different formats can be consulted. The first format is the eishabon
影写本version of the document. eishabon are elaborate copy-books of documents written with brush (môhitu毛筆), they were made before the War when photographs were not yet frequently used for historical research. About 7,000 volumes containing perhaps 200,000 medieval historical documents are arranged in the institute. Now, because of their value, we must get permission from their legal possessors to release them on the internet. As a result of this, only two series are available, namely the Toji-hyakugo-monjo and the Daitokuji-monjo. On the other hand, these two series are some of the most important historical manuscripts of medieval times. Since we are negotiating with other document possessors, mainly Buddhist temples or Shinto shrines, I hope we will be able to offer more series in the near future. If you want to see the eishabon image file, you need a software that can read TIFF G4 image files, as mentioned on our home page.The second format is a photo-image of the document. Recently released is a photograph of the Irikiin-monjo, which was compiled and translated into English by ASAKAWA Kan’ichi. This file is a "j-peg" image file. In the not too distant future all documents possessed by the institute, for example the Shimazu-monjo, will have their photo-image on the internet.
2. Full-text database of historical materials.
We have two full text databases of medieval documents on the Web site of the Historiographical Institute. These can be accessed almost in 1 or 2 seconds, even from Europe, which is much faster than the Image databases. Of course you cannot get whole texts from this system, because it is only a KWIC (Key Word In Context) search system. What you get is a 20 character-line including the keyword in its center, but you can get complete information on where a word, or a single character appears in various documents.
The first database is "Full-text Database of Japanese old archives" (Komonjo Full-text Database
古文書フルテキストデータベース). We started building up this database last year with the help of a Government Grant for the promotion of scientific research. Currently our database consists of the complete content list of the Dainihon-Komonjo-Iewake2, including a total of 120 volumes and about 42,000 documents, and the full-text of several books from this series3. We are still in a very early stage, but with governmental aid, I expect that we will finish this work within the next 10 to 15 years.The second database is a " Full text Database of Heian-period historical materials" (Heian-jidai Full-text Database平安時代フルテキストデータベース). It now consists of the Heian-ibun4, compiled by TAKEUCHI Rizô, and the text of several books that are incorporated in the Dainihon-Kokiroku5. Furthermore, a CD-ROM of Heian-ibun has been published6. This CD-ROM gives information not only for a certain keyword, but also for relevant texts. In Japanese history the Heian-period is appreciated for its classical culture. Since I myself major in Heian history, I expect this database to promote historical studies that are conducted not only by historians, but also by researchers in literature or religious history. I really do think that at the moment we can also integrate literary works, such as the Genji-monogatari or the Konjaku-monogatari in these databases, and with that will have reached a new stage in historical research. Furthermore, we are planning to input the Kamakura-Ibun7, another compilation by TAKEUCHI Rizô. When accomplished, research in medieval history will change rapidly.
3. Catalogue Database of Historical Documents.
We also have two catalogue databases, the "Catalogue Database of the Historiographical Institute's Library" (Shiryô-mokuroku Database
「史料目録データベース」), and the "Catalogue Database of Historical Archives" (Komonjo-mokuroku Database「古文書目録データベース」). The "Catalogue Database of the Historiographical Institute's Library" is a catalogue database of our departmental library. All the data on every single historical document, manuscript, picture, eishabon, and photo-book on historical documents (total of 26,475 volumes) that our library possesses, were recently computerized at high speed. Therefore, now, this database has an important status among our databases. For instance, by inputting the name of a document owner, you get all the information on researches ever done since the Historiografical Institute was founded. It is very useful for historians and archivists. The Image Databases mentioned above are linked to this database and are normally accessed from this site.The second database, or the "Catalogue Database of Historical Archives", is a database limited to eishabon only. This database arranges and names the eishabon documents according to the original structure and rank of archives, its series, fond, cell, etc. Consequently, only an archivist who has enough paleographical knowledge can do the necessary preparations before inputting the data. Moreover, we need to identify the various documents by their name, and only then can we link the image-data, full-text-data, and the manuscripts themselves. To make a catalogue of 200,000 documents is not a simple work. We have received the Government Grant for the promotion of scientific researches for about 8 years, but even now, we cannot say exactly, when this work will be finished.
I have given you a simple explanation on some of the databases available on our Web site. Because of my own specialization my explanation was limited to those databases that contain information on medieval documents. However, in case you specialize in Japan’s modern history for example, and you are especially interested in the history of international relations between Japan, Asia and Europe, you can find databases on our Web site that might be interesting and useful to you8. Unfortunately, I am not the right person to introduce these databases. So instead, I would like to say something about what I think to be major issues concerning full-text databases.
In fact, I must admit that when I started these database projects, I was inspired by a lecture made by Leopold GENICOT in 1982, during his visit to Japan, which is translated into Japanese9. He said in his lecture that if you want to use the computer for historical studies, document criticism, restoration, exact compilation and interpretation, historical materials must be fully put into machines.
Figure 1 bellow is an example of a list for the term "defensio" in all Belgian historical documents before 1000 A.D., which he showed in his lecture. What we want to do is to build up a similar system for treat Japanese medieval documents. Figure 2 is almost similar to figure 1, and is an example for a list of the term soku
束, which means a "bunch of rice grass with grains", retrieved from our system. This term often appears in documents from the 8th century to the first quarter of the 11th century, when tax-payment mostly took this form. After this period this term almost disappeared from documents because tax or rent was from then on paid by the straw bag (tawara俵). Thanks to this list we can thus determine this important change. In fact, I wrote a paper concerning tax systems in the Heian-period in Japanese early medieval times using this list10.Next, I would like to report on some technical problems that we have to clear. First of all there is the problem of processing all these documents. Transferring complex forms of Japanese archives to a digital format is not an easy task since the use of a digital scanner is impossible.
We use the HTML as the input format, and the full text retrieval system for the main database11. As a result of this, we are able: 1) to use the published list of contents (mokuji
目次) in order to make the hyper links to the relevant text, 2) to build a KWIC search system of our institute on the Web site, and 3) to read various notes attached to the text supplying incidental information or indicating wrong characters by clicking the highlighted word.As you know, the biggest problem in building databases is to pre-process the documents for input. But thanks to this system and to the existence of data input companies, we do not have to bother with this task. Now, we simply hand in books to a data input company. Nevertheless, various obstacles to complete the full-text database still remain. The most difficult thing is to manage the special characters (gaiji
外字) which are not supported by our operating system. In fact, we have no solution to this problem. Or rather, it must be treated in a wider scale as I will mention later. The only thing that we, researchers, could do to contribute to the solution of this problem was to make a list of special characters necessary for managing medieval Japanese documents. And that we did.That's about all that I can say about our project. The only thing left for me to discuss is some of my ideas on how we can ameliorate and expand the system.
First of all, there is the problem of mistakes, which necessarily occur when compiling and publishing documents and then again transforming the documents to digital data. We are realists, that is, we can not guarantee a 100% correctness of our digital data, especially in our first stage. The reason for this is, to tell the truth, a lack of time to proofread the numerous galleys, which usually are more difficult to read than ordinal typography. Of course, the main purpose of our institute is to present correct, if possible completely correct texts, but under the present circumstances this can only be achieved in as far as printed matters are concerned, and not yet in digital data. At this moment we still put emphasis on accumulation and the opening of documents. From the historian's perspective the main role of a database system in this time is to provide a search system, rather than an absolutely correct text.
Secondly, we have to think on how to promote the computerization of documents for other Japanese historical periods, but I don't have any concrete ideas on this point. At first, as you know, ancient Japan has important documents, for example the Kojiki『古事記』, Nihonshoki『日本書紀』, and Rikkokushi『六国史』, among others, but these are not digitalized, and if they were it would be difficult to make them accessible on a network because of copyright limitations. However, I expect this problem to be solved in the near future. A more difficult problem concerns the accumulation and presentation of the digital data of documents of Japan’s Early Modern times (so called Edo-jidai江戸時代). These days there are so many documents that we don't yet have a total plan of how to manage the digital data of these documents. I think this may be solved by two ways. The first way is to transform microfilm data to digital data or image data that can be opened directly on the internet, or to CD-ROM that can be double copied for offering. This should be done by each public institute that possesses documents. Secondly, the form of compilation itself has to be changed. In the near future, the major form of compilation of documents from Early Modern times must be done on the Web site, although the publication of books will remain a necessity.
Thirdly, there is the problem of gaiji. It is obvious that we must have a list of gaiji with cords and fonts to print or display on computer. Moreover we want to be able to use these characters freely on the computer. But, as I referred above, this problem concerns various branches of computer techniques and various disciplines within historical research. Currently in Japan several projects are in progress, I heard, such as e-Kanji
e-漢字, edited by KATSUMURA Tetsuya, of The University of Kyoto (see his homepage).We have not yet decided on a policy concerning gaiji. In the “Heian-period database”, we display a black square (
■) for each gaiji. But in the "Japanese old archives database”, begun last year, we are planning to display the character number of the Morohasi-Daikanwa (MOROHASHI Tetsuji, Daikanwa-jiten諸橋轍次『大漢和辞典』) instead of a black square(■). This we do in anticipation of the completion of the above mentioned projects, which will make it possible to replace these character numbers again by gaiji.Obviously, it will be a great problem for European Japanologists, because in the tradition of Oriental Studies they do not only deal with Japanese but often also with Chinese documents. As for Japan, the "gaiji problem” is of a great importance and that concerns the relations between the academies of Japan and other East Asian countries.
NOTES)
1. This paper was originally presented at the 9th annual conference of the European Association of Japanese Resource Specialists, which was held on 23-26 September in Katholieke Universiteit Leuven Belgium. But I added some comments and notes to this report.
2. The Dainihon-komonjo Iewake
『大日本古文書 家わけ』 Ed. Tôkyô-daigaku Shiryô-hensanjo. Tokyo: Tôkyô-daigaku Shuppannkai, 1901-.3. Toji-hyakugo-monjo
『東寺百合文書』 12 volumes ( 1 volume accessible in this database); Daigoji-monjo 『醍醐寺文書』 13 volumes ( 1 volume accessible); Daitokuji-monjo 『大徳寺文書』 17 volumes, ( 1 volume accessible); Todaiji-monjo 『東大寺文書』 16 volumes ( 1 volume accessible); Iwashimizu-hachimangû-monjo 『石清水八幡宮文書』 6 volumes ( 2 volume accessible).4. Heian-ibun
『平安遺文』 (“All Heian Archieves”) compiled by TAKEUCHI Rizô 竹内理三. Tokyo: Tokyo-do.5. Dainihon-Kokiroku
『大日本古記録』 (The “Japanese Historical Diaries”) compiled by the Historiographical Institute and published by Iwanami-shoten. Available in this database is Kyureki 『九暦』, Teishinkoki 『貞信公記』, Shoyuki 『小右記』, Midokanpakuki 『御堂関白記』, Gonijo-Moromichiki 『後二条師通記』 and others.6. Compiled by TAKEUCHI Rizô
竹内理三, and transformed by the Historiographical Institute.7. Kamakura-ibun
『鎌倉遺文』 (“All Kamakura Archieves”) 45 volumes, Tokyo: Tokyo-do8. Ishinshiryô-kôyô Database
『維新史料綱要データベース』 (“Database of Meiji
Restoration”).
Image data of the Historical Documents Relating to Japan in Foreign Countries :An inventory of Microfilm Acquisitions in the library of Historiographical Institute (Hihonkankei-kaigaishiryô-Mokuroku 『日本関係海外史料目録』14 volumes). The "Database of letters exchanged between Japan and Netherlands in Tsushinnzenran 『通信全覧』and Zoku-Tsushinzenran 『続通信全覧』". Shimazukebon Ryukyu-Gaikokukankei-monjo Database島津家本『琉球外国関係文書』データベース (The full-text database of "Shimazu archives relating to Ryukyu and foreign countries"). This database is on the homepage of YOKOYAMA Yoshinori 横山伊徳) .9. Rekishigaku no Dentô to Kakushin
『歴史学の伝統と革新』 ("Tradition and Innovation in History"), edited by MORIMOTO Yoshiki, Kyûshû Digaku Shupan-kai九州大学出版会, 1984.10. Beitô-nengu no Shuno to Inanio-Kinsadame
「米稲年貢の収納と稲堆・斤定」(『鎌倉時代の社会と文化』 東京堂出版、一九九九年)11. This HTML full-text system was made by the “Government Grant for the promotion of scientific research”
(「WWWサーバによる日本史データベースのマルチメディア化と公開に関する研究」代表:加藤友康).
FIGURE 1
FIGURE 2
2.2.1.1 JavaScript
による全文検索システムについて
横 山 伊 徳
別稿で歴史学にとっての
HTML論についてふれたので、本補論ではそれを補う意味で、JavaScriptのもつ意味について簡単に言及しておく。なお、この小論は、98年9月に所内で行なった『HTML&JavaScriptで作る全文検索システム』セミナーの原稿である。
(1)HTML
|
<html> ↑ページを構成する<head> ↑ページの<title> ↑ページの名称 性格を記述</title> ↓(なくてもよい) する部分</head> ↓通常は実体なし<body> ↑ページの具体的</body> ↓中身を記述する部分</html> ↓ファイル全体 |
で構成される、テキストファイル
。2)
拡張子******.html/*****.htm
3)
リンクテキストの中にあって、ファイルを呼び出す機能。
HTMLではもっとも重要な機能である。ページを呼び出す
<a href=”****.htm”>指定のページ</a>イメージを呼び出す
<img src=”image_filename.gif(or jpg)”>
<a href=”*****.gif”>
指定のイメージ</a>
(2)JavaScript
JavaScriptの書式を簡潔に表せば、次の通り。
|
<html> ↑ページを構成する <head> ↑ページの <title> ↑ページの名称 性格を記述 </title> ↓(なくてもよい) する部分 <script language=?JavaScript?> ↑JavaScriptの </script> ↓実体 </head> ↓通常は実態なし <body> ↑ページの具体的 </body> ↓中身を記述する部分 </html> ↓ファイル全体 |
すなわち、
<head></head>の部分に<script……></script>で囲まれた記述をもつ、HTMLファイルである。したがって、JavaScriptの最大の特徴は、プログラム部分もデータ部分も一括して受け渡して、すべてブラウザの機能としてプログラムを実行するという点にある。欠点:データ分だけファイルが大きくなる。バージョンアップが激しく、ブラウザによって使える機能がバラバラ。常に最新のブラウザを用意した方がよい。
長所:ネットワークにつながらなくても利用できる。プログラム言語として、早い、安い、簡単。
従って、多少ファイルが大きくても困らない、ローカルな利用に限定するならば、
JavaScriptで作成する全文検索システムは使いやすいのではなかろうか?
(3)
全文検索システム1)
プロトタイプこのプログラムは、
97年度出版物紹介のページ/publication/index.htmで使われている。2)
全体的なながれ<HTML>
<HEAD>
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=Shift_JIS">
<SCRIPT LANGUAGE="JavaScript">
<!--
|
検索データ読み込みプログラム |
function MakeArray(n){
this.length=n;
var j;
for (j=1;j<=n;j++)
this[j]=" ";
}
var index=new MakeArray(
2);index[1]="
大日本古文書 家わけ第十七 大徳寺文書別集 真珠庵文書之四 本冊は『大徳寺文書別集』(中略) 主担当者、保立道久";index[2]="
日本關係海外史料 イエズス会日本書翰集 訳文編之二(上) (中略) 担当者 五野井隆史・浅見雅一・大橋明子";|
検索プログラム |
function find(f){
var i,URL,h,disp,INDEX;
h=0;
disp="" ;
for (i=1;i<=
2;i++){n=index[i].indexOf(f);
if (n>=1){
URL="p"+i+".htm";
INDEX=index[i].
substring(0,100);disp=disp+"<A HREF="+URL+">detail</A>"+INDEX+".....<P>";
h=h+1;
}
}
|
検索結果表示プログラム |
document.write("<HR>検索終了 : 「"+f+"」に関係する出版物は、"+h+" 冊あります。<P>");
document.write("<A HREF='index.htm'>[
再検索 ]</A><HR>");document.write(disp);
}
//-->
</SCRIPT>
</HEAD>
<BODY TEXT="#000000" BGCOLOR="#FFFFFF" LINK="#0000FF" VLINK="#551A8B" ALINK="#0000FF">
|
問い合わせ画面 |
<center><h1>
東京大学史料編纂所出版物検索(97年度-)</h1></center><BR>
<HR WIDTH="100%"><FORM METHOD="post" onSubmit="return find(forms[0].elements[0].value)">
キーワードによる検索 (登録数2) <INPUT TYPE="text" NAME="keyword" > <INPUT TYPE="button" VALUE="SEEK" onClick="find(forms[0].elements[0].value)"><P></FORM>
<UL><A HREF="p1.htm">
大日本古文書 家わけ第十七 大徳寺文書別集 真珠庵文書之四</A><P><A HREF="p2.htm">
日本關係海外史料 イエズス会日本書翰集 訳文編之二(上)</A><HR WIDTH="100%">
<BR>
</BODY>
</HTML>
この
htmlファイルをindex.htmとして保存する。そして、ブラウザから開くと、全文検索システムが起動する。
2.2.2
「入来院家文書」の公開
近
藤 成 一
1.「入来院家文書」について
「入来院家文書」は薩摩国入来院の地頭入来院家に伝来したもので、平安末期久安
3年(1147)より江戸初期慶長19年(1614)までの文書283通(錯簡により分離したものをそれぞれ1通と数える)からなる(ただし元来は永利家・武光家に伝来した文書が含まれる。平安期のものは元来永利家に伝来したものである)。入来院家は相模国渋谷庄の地頭渋谷氏の出身で、渋谷重国の孫定心が宝治元年(1247)に入来院地頭職に補任されたことに始まる。鎌倉時代から江戸時代まで同一地域を支配しつづけた領主の文書として「入来院家文書」は貴重であり、幕府発給文書や譲状・置文、さらには検注帳など豊富な内容を誇っている。「入来院家文書」は
1929年、エール大学助教授(のち教授)朝河貫一によって英訳が刊行されたことによって、世界的に知られることになった。朝河の著書The Documents of Irikiは、「入来院家文書」を中心として関係史料を英訳したものであるが、詳細な注記がつけられ、また冒頭に概説が付されて、全体を通読することによって、日本における封建社会の展開過程が一望できるように編述されている。マルク・ブロックやオットー・ヒンツェのような比較史家がこれによって日本の封建制に関する認識を深めた。朝河は
1948年にアメリカで死去したが、その偉業を顕彰するために、The Documents of Irikiの復刊が企画され、日本語釈文については原文書にあたって全面的に改訂されることになり、その作業を行うために鹿児島の入来院家より東京大学史料編纂所に古文書原本が搬送された(ただし作業には多くの所員が従事したが、作業主体は史料編纂所ではなく朝河貫一著書刊行委員会である)。その後1966年「入来院家文書」は正式に国に購入され、史料編纂所に所蔵されることになった。しかしいかなる理由によるものか、「入来院家文書」の写真帳は近年まで製作されず、1960年に製作された影写本12冊が一般の利用に供されてきた。1997年史料編纂所に画像史料解析センターが開設されるにあたり、その古文書画像解析分野の最初のプロジェクトとして「入来院家文書」の画像公開が企画された。98年は朝河の没後50周年、99年はThe Documents of Irikiの刊行70周年である。このときにあたり、縁あって「入来院家文書」を継承した史料編纂所は、新しい技術インターネットによって、朝河の志を再びよみがえらせようとしたのである。
2.「入来院家文書」の画像データについて
史料編纂所が所蔵する「入来院家文書」は古文書原本
283通のほかに系図2巻2冊、「清色亀鑑」12冊からなるが、そのうち古文書原本283通について1997年7月撮影した。使用したのは35mmカラーフィルムである。そしてフィルムからのスキャンによってデジタルデータを作成した。画像デジタルデータは
2種類製作した。1つは画像解析研究用の精度の高いデータで、16ベースプロフォトCD仕様で製作した。もう1つは公開用に転送速度を速めるためにファイル容量を小さく抑えたデータで、JPEG仕様で製作した。
3.「入来院家文書」のホームページ
「入来院家文書」のホームページは、画像・日本語釈文・英文をリンクさせるものとして設計した。ただし英文は「入来院家文書」の全点を網羅しておらず、逆にそれ以外の関係史料を含んでいる。日本語釈文および英文は
1955年に日本学術振興会から刊行された『入来文書』The Documents of Irikiを底本としてデジタルデータ化を行った。なお本書を底本として日本語釈文・英文のデジタルデータを製作しインターネットにより公開することについては、日本学術振興会の許可を受けており、1929年版を刊行したエール大学出版会は版権を主張しないことを確認している。「入来院家文書」のホームページは日本語版と英語版が用意されており、相互にリンクしている。以下、日本語版・英語版の順に説明を加え、その後画像表示について説明する。
3.1. 日本語版ホームページ
日本語版カバーページ(図
1)には[釈文] [入来院家文書解題] [HOME]の3つのボタンが並んでいる。そのうち[釈文]のボタンをクリックすると図2の画面が現れる。4つのフレームに分れているが、左上が目録、右上が本文、右下が注記の領域であり、左下は他ページ(「入来院家文書」のカバーページと史料編纂所のカバーページ)とのリンクの領域である。目録・本文は相互にリンクしており、また各フレームをスクロールすることにより、目録・本文いずれの領域においても全文書を任意に選択することができる。
目録の領域において任意に選択した文書名をクリックすると、本文の領域に該当する文書の本文が表示される。また本文の先頭行には文書の通番が#***の形式で示され(原本*―*)の形式で原本の整理番号が併記されている。本文の領域からこの原本の整理番号をクリックすると、目録の領域に該当する文書の目録名称が表示される。通常の用い方は目録の領域で文書名により必要とする文書を検索し、該当する本文を表示させるというものであろうが、本文の領域をスクロールさせていって任意の本文から該当する目録名称を表示させることも可能である。特に英語版ホームページからのリンクで本文領域に入ってきた場合、それから目録名称を表示させるという使用法が考えられる。
注記の領域には底本で傍注とされている情報が表示される。傍注が付されている語句には注記へのリンクがはられているので、本文の領域でリンクのはられている語句をクリックすると、該当する注記情報が注記の領域に表示される。
本文の領域には各文書の本文の最末に
[イメージ][英文-#**]のボタンが表示されている。[イメージ]をクリックすると画像データを表示し、[英文-#**]をクリックすると英語版ホームページに切り替わり、該当する英文を表示する。[イメージ]ボタンはすべての文書に表示されているが、[英文-#**]ボタンは表示されていない場合がある。これは朝河の英訳が「入来院家文書」全点を対象としたものではないため、該当する英文が存在しないものである。「入来院家文書」には若干の錯簡があり、
1通の文書が分離して別に成巻されている場合がある。そのような場合、目録データは便宜複数のデータとして採録している。たとえば第11巻・第13巻の目録データはつぎのように表示されている。
11
入来院家文書 十一 1巻(
外題)庁宣留守所ヨリ周頼在判迄 廿二通 十九番(内容)
1
正嘉2年9月 日 薩摩国司庁宣 (#122)(中略)
9
元亨4年12月16日 鎮西裁許状 1/3 (#130)10
元亨4年12月16日 鎮西裁許状 3/3(#130)(下略)
13
入来院家文書 十三 1巻
(内容)
1 (
年月日欠) 鎮西裁許状 (#158)2
元亨4年12月16日 鎮西裁許状 2/3(#130)(下略)
上記のうち第
11巻の9・10と第13巻の2は元来1通の文書である。11-9、13-2、11-10の順で継がれていた紙が剥離してばらばらに成巻された。このような場合、目録データでは原文書の現状を尊重して3件のデータとしている。一方、日本語釈文の方は錯簡を正してある。従って上記の文書の場合には、本文の先頭行には釈文の通番と原本の整理番号が
#
130(原本11-9)(原本13-2)(原本11-10)というように記されている。目録の領域で
11-9、13-2、11-10のいずれをクリックしても本文の領域には通番#130が表示され、逆に本文の領域からは(原本11-9)(原本13-2)(原本11-10)のいずれかをクリックすることによって、目録の領域に該当データが表示されることになる。つまり目録データと本文データは多対一対応になっている。
 図1 日本語版カバーページ
図1 日本語版カバーページ
図2 日本語版釈文のページ
3.2. 英語版ホームページ
英語版カバーページ(図
3)には[ENGLISH TEXT] [EXPLANATORY NOTES] [HOME]の3つのボタンが並んでいる。そのうち[ENGLISH TEXT]のボタンをクリックすると図4の画面が現れる。3つのフレームに分れているが、左上が目次、右が本文の領域であり、左下は他ページ(「入来院家文書」英語版・史料編纂所・東京大学それぞれのカバーページ)とのリンクの領域である。英語版ホームページは
The Documents of Irikiの目次と本文をそのままデジタル化したものである。したがって「入来院家文書」全点の英訳ではなく、逆に「入来院家文書」以外の関係史料の英訳も含まれている。また配列は原文書の配列とは異なり、原則として編年に直されている。本文の領域には各文書の本文の最末に
[IMAGE][JP-#**]のボタンが表示されている。[IMAGE]をクリックすると画像データを表示し、[JP-#**]をクリックすると日本語版ホームページに切り替わり、該当する日本語釈文を表示する。[IMAGE][JP-#**]ボタンが表示されていないのは、「入来院家文書」以外の関係史料であるため、該当する画像・日本語釈文が存在しないものである。
 図3 英語版カバーページ
図3 英語版カバーページ
 図4 英語版本文ページ
図4 英語版本文ページ
3.3. 画像表示
日本語版・英語版いずれかのページの本文領域において
[イメージ]ないし[IMAGE]ボタンをクリックすることにより、該当する画像を表示するページが立ち上がる。1紙1コマを原則として撮影されているので、複数紙からなる文書の場合には1通につき複数件の画像データが存在する。また紙背が撮影されている場合も同様である。このように複数件の画像データが存在する場合には、フレームが左右に分割され、左のフレームに全画像データのサムネイルが表示される。そして左のフレームで任意のサムネイルをクリックすることにより、該当する画像の精細データが表示される。錯簡のある文書についても、錯簡が正された状態でサムネイルが表示されるように、日本語釈文ないし英文データと画像データとのリンクがはられている。
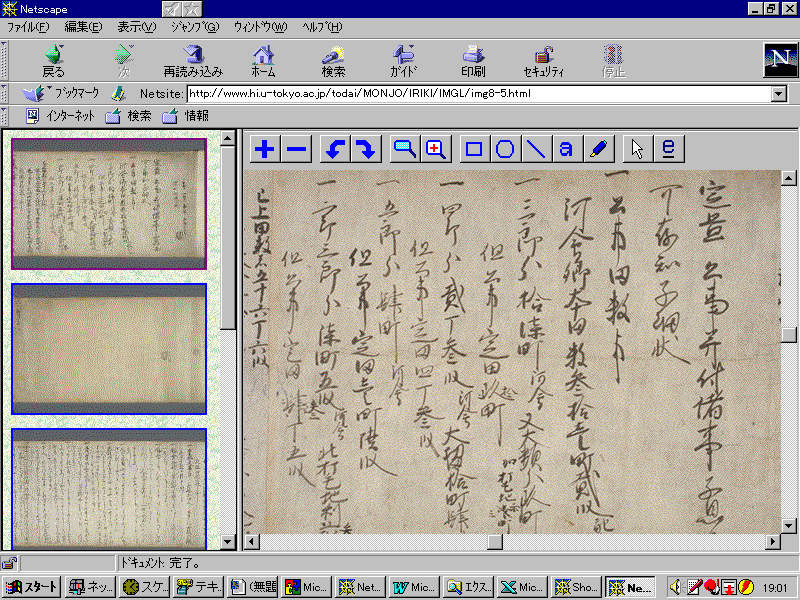 図5 画像表示ページ
図5 画像表示ページ
4. データベースによる利用
「入来院家文書」のデータは、史料編纂所の各種データベースにも提供されている。すなわち「古文書目録データベース」と「所蔵史料目録データベース」に目録データが、「古文書フルテキストデータベース」に日本語釈文データが提供されている。そして「所蔵史料目録データベース」の目録データには画像データがリンクされている。したがって各データベースの特性にしたがった検索の結果として日本語釈文ないし画像データを表示させることが可能である。
5. 課題
日本語釈文も英文も全体が
1ファイルに収められている。そのことによって本文領域をスクロールさせて任意の場所を表示させることができるのであるが、一方でファイル容量が過大となっている。日本語釈文データファイルが384KB、英文データファイルが1114KBであるのでハードウェアには一定の負担となっている。画像表示が日本語釈文ないし英文からのリンクなので、常に錯簡が正された状態で表示される。しかし原本の現状を正確に示すことも必要であるから、目録データから画像へのリンクも実現すべきであろう。
逆に、デジタル画像処理技術を駆使して複数紙からなる文書の画像を結合してみるのも興味深い。その応用として錯簡の補正をデジタル画像上でバーチャルに行うことも可能になる。紙継目に書かれた文字が錯簡によって泣き別れになっている場合など、この処理によって再び判読可能になると期待される。ただし画像処理をどこまで行うかという新たな課題も包含されている。
史料編纂所では現在、「入来院家文書」
CD-ROM版の刊行を準備している。上記の課題のうちのいくつかは、CD-ROM版企画のなかで具体的に検討されている。
2.2.3
『大日本史料』第十編之二十二編纂ノートの公開
中 島 圭 一
現在、史料編纂所のホームページにアクセスして、中世史料部のページを開くと、第十編の項から「編纂ノート」を見ることができるようになっている
(http://www.hi.u-tokyo.ac.jp/chusei/10hen.html
)。本稿は、この編纂ノートの公開の周辺事情について報告し、あわせて編纂ノートの内容を紙上で紹介しようとするものである。『大日本史料』は「古代の朝廷によって編纂された六国史(
887年までの歴史を記述)のあとをうけて、明治維新までのおよそ980年の間の日本史上の事件を年月日順に掲載し、それに関する史料(日記・古文書から随筆・雑著の類まで)を原文のまま収載するもの」(史料編纂所ホームページの出版物紹介)であり、史料編纂所の編纂事業の中でも基幹となるものの一つである。しかし、1901年に刊行が開始されて以来の、史料集としての体裁は、必ずしも十全のものであったわけではない。事件の概要を記した綱文の後に関係史料を配列し、必要に応じて傍註・標出・按文を配して説明を加えるのだが、それだけでは考証の内容を十分に表現できない場合がしばしば生ずるのである。このため、私自身、読者として『大日本史料』に接した時には、史料の年次や登場する人名の比定の根拠がはっきりせず、記載内容を信じてよいものかどうか迷った経験がある。そこで、担当の『大日本史料』第十編之二十二が
1997年に出版されたのを機会に、編纂にあたって作成したノートの一部を、史料編纂所のウェブ・サイトを通じてインターネット上に公開することを試みた。この方式の利点としては、所報・紀要その他の出版物に掲載するよりもはるかに容易かつ迅速に発信できること、誤りの指摘や新情報の提供を得た場合にすぐ訂正や追記が可能なことが挙げられよう。ただしその一方で、まだ日本史研究者の間でインターネット利用者の数に限りがあること、編纂ノートの内容を論文等に引用するには問題があること、などの欠点もある。前者の状況を端的に示すのが、既に所内外から編纂ノート公開について好意的な反応が寄せられてはいるものの、その数が必ずしも多くはなく、内容の訂正・追記を迫るような申し入れに至っては未だ全くない事実であろう。また後者の問題とは、具体的には、書き換えや消去が容易であるだけに、ある時点における記述内容が将来も保存されている保証がなく、論文を読んだ人などがもとの編纂ノートを読めるとは限らないことである。
日本史研究者の間でのインターネット普及は、各地の研究機関等で行われているデータベースの公開などがさらに進展し、「便利な道具」として認知されていくとともに、今後ゆるやかに達成されていくものと思われる。しかし、記述内容の固定については、特に歴史学のように知識・情報の蓄積が重要な分野においては、早期に意識を強めて対策を講じておく必要があろう。以下に編纂ノートを掲載するのは、単なる事例紹介というだけでなく、この課題にとりあえずの解決を与えようという意味も含んでいる。編纂ノートのインターネット公開は、第十編之二十三以降も続けていく予定なので、その記述の固定・公表方法については、今後さらに検討を重ねて最善を追求していきたい。
[凡例]
①以下に掲げるのは、
②前半部分は、『東京大学史料編纂所報』第
32号に掲載された刊行物紹介とほぼ同文だが、そのまま収録した。③不特定多数を対象としたインターネット公開用のテキストであるため、くだけた表現になっている所がある。
大日本史料第十編之二十二編纂ノート
本冊には、正親町天皇天正二年(一五七四)四月八日より六月十三日までの史料を収める。中央の織田信長の動きとしては、まず近江石部城の攻略がある(四月十三日条)。これにより、長年にわたって信長に抵抗してきた六角承禎・義治父子も、遂に本国を逐われるに至った。羽柴秀吉による今浜城の普請、長浜への改称と合わせて(六月六日条)、近江一国の支配固めが進んでいる。また山城でも、将軍足利義昭追放後に帰服した三淵藤英の伏見城を廃城とし、細川昭元も槙島城から本能寺に移してしまい、塙直政を山城守護に任じてその槙島城に入れている(五月是月条)。しかし、正月以来不安定な越前の情勢はさらに悪化し、前年八月に従兄義景を自殺に追い込み、信長に帰順した朝倉景鏡(土橋信鏡)は一向一揆との戦いで敗死し、同じく信長に従っていた朝倉(篠河)景綱も敦賀に逃れた(四月十四日条、五月二十日条)。武田勝頼も、二月の美濃攻めから一転して遠江に鉾先を向け、高天神城を包囲している(五月十二日条)。このほか、義昭も島津義久を誘うなど(四月十四日第二条)、反信長勢力の活動はますます活発である。
続いて地方に目を向けると、中国方面では宇喜多直家が、旧主で信長方の浦上宗景を破って地歩を固めつつ、毛利氏との結び付きを強めている(四月十八日条)。九州では、正月に龍造寺隆信によって本拠地肥前鏡城を奪われた草野鎮永とその実父原田了栄が、大友宗麟の後ろ盾を得て巻き返しに転じ、肥前・壱岐の諸将の多くを味方に付け、龍造寺氏の孤立化に成功する(五月二十日第二条)。
東日本の動きはさらに激しい。二月以来、関東に在った上杉謙信は、上野の数城を陥れたものの、由良成繁・国繁父子の桐生・新田金山両城は攻略ならず、越後に引き揚げることとなった(四月二十五日第二条)。この間、利根川右岸の拠点である武蔵羽生城に兵粮を入れようとして、川の増水で不成功に終わっているが、その原因は、羽生に赴いて現地を実見しながら、物資搬入の困難を見抜けなかった佐藤筑前守の甘い状況報告にあるとして、「佐藤ばかものニ候」と謙信が感情をむき出しにしているのが興味深い。
この謙信の動きに対応して出馬した北条氏政は、続いて簗田晴助の下総関宿城に向かい、本格的な攻撃に乗り出している(四月二十六日条)。
東北では、一時鎮静化していた最上栄林(義守)・義光父子の争いが再発し、正月にも栄林側に立って出兵した伊達輝宗が、再び義光を攻撃した(四月十五日第二条、五月十一日第二条)。しかし、六月五日に会津の当主蘆名盛興が死去したことから(同日第二条)、情勢を見定めるため、とりあえず矛を収めている。蘆名家としては、田村清顕との戦いで重臣松本氏輔を失った(五月十三日条)のに続く痛手で、隠居の盛氏が須賀川二階堂氏から盛隆を養子に迎えて家督を嗣がせることで、事態の収拾を図っている。
死歿・伝記としては、朝倉景鏡・蘆名盛興・松本氏輔のほか、佐野昌綱(四月八日条)、真田幸隆(五月十九日条)、里見義堯(六月一日第二条)を収録した。いずれも東国で活躍した武将たちだが、中でも里見義堯については、二度にわたる国府台合戦の敗北を乗り越えて安房・上総二ヶ国の大名へと成長した事蹟とともに、『堯我問答』等が物語る日蓮宗富士門流との関係が注目される。
他にも家の継承に関わる事項として、五月十一日条に九条行空(稙通)から同兼孝への所領譲渡を収めている。これはおそらく、二月に兼孝が右大臣となったのを契機として行われたものであろう。
(目次7頁、本文
287頁、本体価格6000円)
天正二年四月三十日 大友宗麟、原田親種ヲシテ自裁セシム
『史料綜覧』には設けられている条だが、削除した。これは、五月二十日条に収めた
(天正二年)二月廿一日大友宗麟書状(『鶴田文書』坤)より、没日が二月十五日であることが判明したため。「原田系図」(『改正原田記』八)が「天正元年二月十五日自殺」としているのは、年を誤ったものだろう。『史料綜覧』は、親種の死亡が天正二年に下るのが他の史料より明らかなことから、「原田系図」を採らず、筑前金龍寺所在の原田親種墓碑銘に「天正弐年四月晦日」とあるのを採用したらしい。このように九州の戦国史には、未解明の部分が極めて多い。中でも龍造寺氏の征服過程は、『史料綜覧』を含めて、これまで軍記の叙述に頼って組み立てられているために誤りが多く、実質的に研究が未開拓な処女地となっている。『佐賀県史料集成』には大量の戦国期文書が翻刻されており、研究の素材には事欠かないので、卒業論文のテーマとしてはお勧め。最近、福岡市立博物館の堀本一繁氏などによってこのフロンティアの開拓が始まっているものの、今ならまだ間に合う!
五月十一日 九条行空(稙通)、子兼孝ニ所領ヲ譲与ス
おそらく二月に兼孝が右大臣となったのを契機に、完全に代替りがなされたのであろう。稙通が出家後十年以上も九条家領を譲り渡さなかった背景には、兼孝が二条家からの養子であるということがあるかもしれない。
五月十一日 伊達輝宗、出羽北条庄中山ニ出陣シ、最上義光ノ邑ヲ侵ス、尋デ、亦、畑谷城等ヲ攻ム
『伊達氏四代治家記録』五月五日条には、中野城主氏淳なる人物が見えるが、伝記不詳である。中野城は山形の北にあり(現山形市内)、城主は最上義時(義光弟、栄林方)なので、『治家記録』編纂者の誤りであろう。この日の記事に登場する若木は山形の西にあり(現山形市内)、前後の『伊達輝宗日記』の記述からみて城主は栄林である可能性が高いが、確証がないので傍註は付さなかった。
五月十二日 武田勝頼、徳川家康ノ将小笠原氏助(長忠)ヲ遠江高天神城ニ囲ム
城将小笠原与八郎の実名については、いくつかの説がある。
・長忠説……近世に作られた系図・軍記類の多くが採用しており、通説となっている。
『大日本史料』も、天正元年十一月四日条ではこれに従った。
・氏助説……本条に収録した『雑録』十一所収文書(『浅羽本系図』四十七にも写があ
る)、『總見記』八など。また長忠説の『武徳編年集成』十四も「初名氏
助」とする。
・氏義説……『大日本史料』元亀二年三月是月条参照。『諸家系図纂』六之二の「氏
儀」は、これの書き誤りであろう。武田信玄に高天神城を攻められた頃ま
での名とみることができる。
他に「氏次」説もある。また、『寛政重修諸家譜』は「氏助」の項を立てて初名を「氏義」とする一方で、小笠原長隆の項では「長忠」と記し、『略譜』も下巻で「長忠」の項を立てながら、上巻の小笠原義信・定信の項では「氏助」、下巻の小笠原朝宗の項では「氏義」とするなど、混乱がある。
本条の編纂にあたっては、写のみで不安はあるが、文書があるということで、「氏助」説を採用した。彼の父は氏興であり、「氏」がこの家の通字と考えられることも大きな理由である。なお「長」は、武田氏によって追放された信濃守護家の府中小笠原氏の通字として知られるので、武田氏に降った後にその名跡を与えられ、「長忠」と名乗った可能性がある。
五月十三日 蘆名盛興ノ将松本氏輔等、田村清顕ノ兵ト陸奥福原ニ戦ヒテ、敗死ス
蘆名家の家老松本図書助の実名を、『史料綜覧』では『伊達氏四代治家記録』に基づいて氏興とするが、この家は「輔」を通字としている模様で、『伊達家文書』
267号などに見える氏輔を採用した。なお、彼の息太郎は、軍記等によれば主家に冷遇されたのに反発し、後に叛乱を起こして敗死することになるが、同じく軍記等によれば彼の実名は行輔で、舜輔・氏輔などと代々拝領してきた蘆名家当主の偏諱を得ることができなかったらしく、冷遇されたというのは強ち軍記の創造ではなさそうである。
五月十九日 武田勝頼ノ将信濃真田幸隆卒ス、子信綱嗣グ
幸隆以前の真田氏の系譜はよくわかっていないので、信憑性が高い順に配列した。なお、『矢沢系図』(長野県上田市矢沢良泉寺所蔵)は、真田右馬佐頼昌の三男が矢沢綱頼であるとしており、綱頼の兄とされる幸隆の父の名を伝える貴重な史料である。ただ、綱頼の実在は確実だが、幸隆弟かどうかは必ずしも確定されておらず(例えば『系図纂要』は幸義弟・幸隆叔父説)、また『大日本史料』という刊行物の体裁の問題もあって、残念ながら収録を断念した。
また、喜山理慶大姉という法名のみがわかっている室については、河原隆正妹と飯富兵部(虎昌カ)女の両説を挙げておいた。ただし、飯富氏は『系図纂要』に信綱母として見えるが、信綱は天文6年生まれなので、幸隆が武田家に帰属する以前に同家重臣の女が嫁してきたことになり、疑問が残る。河原氏についても、この説を載せる『真田家御事蹟稿』の編者河原綱徳と同姓というのが気になるところである。
六月五日 陸奥黒川城ノ蘆名盛興卒ス、尋デ、父盛氏、同国須賀川城二階堂盛義ノ子盛隆ヲ迎ヘテ、家督ヲ嗣ガシム
本条の編纂のために史料の捜索を行ったところ、盛氏から盛興への家督相続の時期がかなり絞られた。永禄六年四月十日新宮熊野神社棟札銘(「新宮雑葉記」『喜多方市史』4巻
546ページ所収)には「当時屋形盛氏嫡男盛興」とあり、翌永禄七年六月日勝福寺銅鐘銘(『喜多方市史』4巻486ページ所収)「大檀那平盛興并隠居盛氏」とあるので、この間に当主の交代がなされたのは確実である。ただ、残念ながら永禄六年・七年のどちらに行われたのかは不明なので、例えば~年是歳に一条を立てることもできない。やむを得ず、永禄七年六月是月に「陸奥蘆名盛興竝ニ盛氏、陸奥勝福寺ニ銅鐘ヲ寄進ス」の条を立てて、これに合叙する形で収めることで、九編の了解を得て連絡按文を作成した。
・中世史料部のページに戻る
August 1997, January 1999; wwwsiryo@hi.u-tokyo.ac.jp
2.2.4
南欧における歴史情報に関するコンピュータ利用の現況
浅 見 雅 一
1. はじめに
近年、インターネットの急速な進歩と普及によって、海外の図書館や文書館にアクセスすることが可能となり、研究の幅が飛躍的に拡大した。これには、各国の諸機関がデータベースを公開したことが大きく寄与している。主なものとしては、国立図書館・文書館、大学図書館等の所蔵書籍の検索システムを挙げることができるであろう。この内、海外の文書館については、ユネスコが作成したサイトが便利である。文書館が中心となっており、図書館には殆どリンクしていないが、図書館を中心とするサイトによってある程度は補うことができる。
*
Archives in the World(http://www.unesco.org/webworld/en/archives.htm)
*
Libraries in the World(http://www.tulips.tsukuba.ac.jp/other/all.html)
歴史研究へのインターネット利用については、例えば、アリアドネ『調査のためのインターネット』(ちくま新書、
1996年)には有名なサイトがいくつか紹介されているので参照されたい。言うまでもなく、インターネットは日々拡大しているので、現在ではサイト数も更に増加していることであろう。コンピュータの学術利用、特に歴史研究への利用は、これまでにも様々な形で論じられているが、外国のインターネットの学術利用を紹介し、基本的問題点を指摘したものは意外に少ない。インターネットの学術利用について、星野聰氏は「インターネットの学術的利用について―とくにアメリカ・イギリスの場合―」(『重点領域研究「沖縄の歴史情報研究」―総括班・沖縄3研究班合同研究会報告書―』1996年)において、コンピュータ利用の先進国であるアメリカ合衆国と連合王国を例にして論じておられる。同論文において、星野氏は、歴史や文学の研究を想定して、インターネット利用の問題点を簡潔に指摘しておられる。本稿では、英語圏と比較すると、それ程には認知されていない南欧におけるコンピュータの歴史研究への利用を採り上げて簡略に紹介する。基本的問題点としては、星野氏が既に指摘されたものに何ら加えるものはない。南欧諸国はキリシタン時代の日本と主にキリスト教布教を通じて関係のあった地域である。かつて松田毅一氏は南欧諸国所在の日本関係史料の概略を紹介されたが
(1)、現在では東京でもそうした史料の一部をマイクロフィルムで閲覧できる(2)。そこで、キリシタン史の研究に有益となるであろう情報を中心として、南欧のインターネット利用の現況を紹介し、今後の可能性を併せて考えてみたい。
2. ヴァティカン市国
キリシタン時代における日本とローマ教皇庁との関係を示す史料は、それ程多くが知られているわけではない。そこで、キリシタン史の研究に必要な個別の情報ではなく、ローマ教皇庁全般についての情報を得る方法を紹介する。ローマ教皇庁は、ホームページを公開している。
*
The Holy See(http://www.vatican.va/index.html)
ローマ教皇庁の所蔵史料については、主要なものとしてはアメリカ合衆国のカトリック系大学セント・ルイス大学が作成したデータベースであるヴァティカン・フィルムライブラリーを挙げることができる。これによって、ヴァティカン図書館が所蔵する稿本類の画像が一部ではあるがインターネットを通じて見ることができるようになった。
*
The Knights of Columbus Vatican Film Library at Saint Louis University(http://www.slu.edu/libraries/vfl/)
図1 ヴァティカン・フィルムライブラリー
3. イタリア共和国
ヴァティカン・フィルムライブラリーは、カトリック関係の諸情報にリンクしている。その内のひとつであるローマのイエズス会本部に付設されているローマ・イエズス会歴史研究所は、ホームページを公開している。
*
Institutum Historicum Societatis Iesu, Roma.(http://space.tin.it/scuola/mmorales/hisi.html)
イエズス会本部には、図書館と文書館が付設されている。同文書館の所蔵文書は概略が示されているに過ぎないが、日本関係文書については詳細な目録が出版されている
(3)。ローマ・イエズス会歴史研究所では、同文書館に所蔵されている文書を基にイエズス会の布教史に関する史料集の編纂と出版を行なっている。既に多数の学術的にも質の高い史料集が出版されている。こうした史料集やその編纂過程において作成されたカードや索引をデータベース化することが期待される。
*
Jesuit Resources on the World Wide Web(http://maple.lemoyne.edu/
~bucko/jesuit.html)アメリカ合衆国ワシントン特別区にあるイエズス会系の大学であるジョージタウン大学では、中世史関係のサイトを作成している。これには、中世史のみならず、キリスト教関係の情報も豊富である。独自のテキストデータベースも格納されている。
*
The Labyrinth(http://www.georgetown.edu.labyrinth/index.html)
4. ポルトガル共和国
ポルトガル文化省のデータベースは、残念ながら現時点では余り機能的とは言えない。例えば、ポルトガル国立図書館は、蔵書の検索システムをインターネット公開しているが、この検索システムを利用する場合には、同図書館のホームページから直接アクセスすることになる。尚、この検索システムは、検索する史料が稿本か刊本かを区別せずに、検索条件を入力して一括変換することになる。
*
Biblioteca Nacional, Lisboa.(http://www.ibl.pt/)
ポルトガル共和国には、キリシタン関係文書が散在している。戦前、岡本良知氏がその概略を紹介されている
(4)。その他、史料を総体的に紹介したものとしては、フィルモテーカの年報がある(5)。フィルモテーカは、ポルトガル文化省がポルトガルの海外進出に関する史料を広く内外からマイクロフィルムの形態で蒐集することを目的として設立された機関である。フィルモテーカでは蒐集したマイクロフィルムを研究者の閲覧に供しているばかりでなく、逐次目録化し、年報の形式で刊行している。リスボン市にあるアジュダ図書館は、
18世紀中葉にマカオで作成された写本集 Jesuitas na Asia を所蔵している(6)-(7)。同写本集のマイクロフィルムは、東洋文庫と東京大学史料編纂所に各々全巻が、上智大学キリシタン文庫に日本関係の一部分が架蔵されているが、著名な史料であるにも拘わらず、整理は余り進んでいないのが現状である。リスボン市にあるトーレ・ド・トンボ国立文書館は、世界的にも最大級の文書館として知られているが、その所蔵史料は膨大さ故に著しく整理が遅れている。同文書館では、所蔵文書を逐次マイクロ撮影し、整理する作業が進められている。同文書館は、ポルトガル領インドから本国に送付された公文書である「モンスーン文書」の
17世紀前半までの部分を所蔵している。「モンスーン文書」の日本関係史料については、高瀬弘一郎氏が翻訳、紹介しておられるが(「ゴアのインド領国歴史文書館収蔵の『モンスーン文書』について」『古文書研究』第3号、1970年)、その他にも同文書館所蔵の日本関係文書の目録が作成されている(8)-(10)。現時点では、ポルトガル共和国における歴史情報のコンピュータ利用はそれ程には進んでいないようである。蔵書の検索システムをインターネット公開している大学図書館は、ごく限られている。しかも、大学や史料の所蔵機関では、ホームページを公開しているところさえも少ないのが現状である。
澳門文化司署では、トーレ・ド・トンボ国立文書館等の機関と共同でマカオ関係を中心とする東アジア史料の目録化を進めている。同文書館が所蔵する漢文文書の目録は、その成果のひとつである
(11)。リスボン市にあるポルトガルの植民地関係文書を所蔵している海外領土史文書館の「マカオ部」の目録が、既に出版されている(12)。その他、マカオ市歴史文書館の所蔵文書についても目録化が進められている(13)。この様に、既に蓄積されている史料目録やマイクロフィルムを画像処理し、コンピュータ利用していくことが今後の課題となるであろう。マカオ中央図書館でも、蔵書の検索システムをインターネット公開している。蔵書数は決して多いとは言えないが、マカオ関係書籍を調べるためには有益である。マカオ関係のデータベース公開を計画しているようなので、将来に期待したい。
*
Biblioteca Central de Macau, Macau 澳門中央図書館(http://macau.ctm.net/
~kentng/)
5. スペイン国
スペイン国の学術情報は、スペイン教育・文化省のホームページから各々のデータベースにアクセスする仕組みになっている。これは、地方の公共図書館・文書館、一部の大学図書館にもリンクしている。この方法は、学術ネットに掲載された不正確な個人情報を排除するためには、ある程度有効であるのかも知れない。尚、スペイン国のアジア関係史料については、所蔵機関毎に簡潔に纏められた目録が出版されている
(14)。*
Ministerio de Educación y Cultura(http://www.mcu.es/homemcu.html)
スペイン教育・文化省のリンク集は、スペイン文化省の案内に掲載されている情報が基本になっている。スペイン国立図書館を始め、国立の博物館、美術館、劇場、映画館等、スペイン文化省の管轄に属する諸機関にリンクしており、その内の数機関はデータベースを格納している。但し、スペイン教育・文化省のホームページは、管轄外となる機関のものは含まず、リンクさえしていない。王立歴史学士院図書館
(15)-(18)、王宮図書館、エル・エスコリアルのサン・ロレンソ修道院図書館等についは対象外となる。 図2 スペイン教育・文化省
図2 スペイン教育・文化省
スペイン国立図書館は、蔵書の検索システムをインターネットで公開している。この検索システムは、刊本は
1831年を基準として出版年代によって新旧に分類しており、その他のものは、稿本、地図、絵画等の品目によって分類している。*
Biblioteca Nacional, Madrid.(http://www.bne.es/)
この検索システムによって、同図書館から出版された目録類がなくとも容易に所蔵資料を調査することができるようになった。同図書館は、新大陸関係の史料を多数所蔵しているが
(19)、日本関係史料も若干ではあるが所蔵している(20) (21)。スペイン国及びラテンアメリカ諸国で出版された書誌としては、Antonio Palau y Dulcet, ed., Manual del Librero Hispanao-Americano, segunda ed., 28vols., indices 7vols., Barcelona, 1948-87. が詳細で有用であるが、所蔵機関は示されていない。インターネット公開されている図書検索システムと併用すれば、この書誌の所蔵機関の補完が可能となるであろう。スペイン国には、スペイン国立歴史文書館
(22)(23)、シマンカス総合文書館(24)、インディアス総合文書館(25)のいわば三大文書館がある。各文書館のホームページには、所蔵する文書群の概略が示されている。マドリード市にあるスペイン国立歴史文書館には、Clero Jesuitas という文書群に多数のイエズス会関係文書が収集されているが、あとの二文書館は公文書の所蔵機関であるので、教会史料は断片的なものでしかない。*
Archivo Histórico Nacional, Madrid.(http://www.mcu.es/lab/archivos/AHN.html)
*
Archivo General de Simancas, Simancas.(http://www.mcu.es/lab/archivos/AGS.html)
*
Archivo General de Indias, Sevilla.(http://www.mcu.es/lab/archivos/AGI.html)
セビーリャ市にあるインディアス総合文書館は、シマンカス総合文書館からスペイン国の植民地関係文書を分離したものである。それ故、シマンカス総合文書館には、スペイン国の内政関係文書が所蔵されている。インディアス総合文書館では、フィリピン関係史料に日本関係史料が散見される
(26)。1986年から、同文書館では、所蔵文書をデータベース化するプロジェクトを推進している。このプロジェクトには、スペイン教育・文化省、スペインIBM、ラモン・アレセス財団 Ramon Areces Foundation が共同出資している。ラモン・アレセス財団は、スペイン国における有数のデパート・チェーンであるエル・コルテ・イングレスの所有者が設立した財団である。このプロジェクトのためにマドリード自治大学内にプロジェクトセンターが設置され、実際の作業が行なわれている。このプロジェクトの基本的課題は、
(1)膨大な量になる文書の閲覧・コピーの要求に対応すること、(2)これまで利用されてきた目録類をデータベース化して文書の検索を機械化すること、(3)閲覧に際して生ずる文書の破損等に対応し、利用者が文書を直接利用するのではなく画像情報として利用できるようにすることであった。(2)は2世紀にわたる未刊の目録類を含み、研究者の文書に関する情報も入力していくということである。(3)は同時に、閲覧者は必要箇所を瞬時にして目にすることができるという利点が生じることを意味する。以上の課題を解決するために、データ処理グループと画像処理グループが編成され、両グループが作業を並行して行なうことになった。その結果、同文書館では、画像処理された文書や地図類については、閲覧者はコンピュータ画面を通じて検索し、スクリーンの画像を閲覧することになっている。勿論、必要箇所のコピーも容易である。更に、スペイン国立歴史文書館とネットワークで繋ぎ、画像入力したものについては相互に閲覧が可能なシステムの構築を検討している。現在のところ、こうした閲覧は、インディアス総合文書館内に限られているが、将来的にはインターネットによる公開を目指しているということである。尚、市村佑一氏が「古文書のデータベース化とマルチメディア」(『日本歴史』第
559号、1994年)として、このプロジェクトの概略を紹介されていることを附記しておきたい。
6. 修道会の情報
南欧の特徴として、学術情報を大学や政府機関が独占するのではなく、教会や修道会がそれに関与することが挙げられる。イエズス会については既に採り上げたが、托鉢修道会についても例外ではない。次に、フランシスコ会、ドミニコ会、アウグスティノ会のホームページアドレスを示すことにする。これらの情報は、各修道会の本部が置かれている南欧諸国ではなく、コンピュータの技術が発達した諸外国で作成されたものである。
*
Franciscan Web Page(http://listserv.american.edu/catholic/franciscan/index.html)
*
Dominican WWW home page(http://www-oslo.op.org/op/catalogus/op-homes.html)
*
The Augustinian Order(http://www.geocities.com/Athens/1534/osa.html)
各サイトには、今日における活動の概略が示されている。その意味から、世界各国に散在して活動する修道士個人のホームページにリンクしている。更に、データベースを格納しているものもあり、各修道会の創設者の著作や修道会規則等の基本書籍を見ることができる。
7. 結 び
インターネットの情報が増大することによって、学術情報として粗悪なものが氾濫することが懸念されているのが現状である。実際、作成者不明の情報が学術ネットに掲載されることも少なくない。勿論、個人が作成した情報であっても、良質なものもある。作成者の所属組織や支援機関等を記し、作成の意図を説明していることもある。学術情報の質を管理していくことは、今後の重要課題のひとつとなるであろう。スペイン教育・文化省が学術情報を一括管理しているのは、ひとつの対処方法と言えるかも知れないが、政府機関が情報を管理しようとすることには問題があるとも言えるであろう。しかも、アメリカ合衆国のように、インターネットが著しく発達して学術情報が膨大な量になると、この方法では対処できなくなることが予想される。現時点では、粗悪な学術情報を排除するためには、信頼の置ける情報提供者が作成したサイトからリンクしている情報を探すことが考えられる程度である。
データベースに対して、どの程度の校正がなされているかは千差万別であろう。何らかのテキストを格納している場合、その底本となる印刷物を明記していることもあるが、説明がないことも少なくない。こうした出版とは異なる形態のものを学術情報として研究に利用するためにはルール作りが必要となるかも知れない。史料の所蔵機関については、図書館にしても文書館にしても、史料の整理・研究が進んでいるところほどコンピュータ利用が容易になっている。史料の整理と研究のために史料の所蔵機関が大学と提携する事例も見られるが、多大な経費と人員を必要とするデータベースの作成には、こうした複数機関による共同開発が増えていくことであろう。史料を画像処理してインターネット公開していくことは、校正が大きな問題とはならないこともあり、今後の進展が期待される。史料の所蔵機関によっては、研究のためばかりでなく損傷や防止や災害からの保護のために、史料のマイクロ撮影を進めているところもある。こうした既に継続している事業をコンピュータ利用に転用する方法は、今後も検討されるべき課題となるであろう。
〔附記〕インディアス総合文書館については、同文書館のピラール・ラサロ・デ・ラ・エスコスーラ女史と慶應義塾大学の柳田利夫教授より情報の提供を受けた。
〔参考書誌〕
(1)
松田毅一『在南欧日本関係文書採訪録』(養徳社、1964年)(2)
東京大学史料編纂所編纂『日本関係海外史料目録 12―ヴァチカン市国・イタリア国・ポルトガル国・スペイン国・メキシコ合衆国所在文書―』(1969年)(3)
尾原悟編『キリシタン文庫―イエズス会日本関係文書―』(南窓社、1981年)(4)
岡本良知『ポルトガルを訪ねる』(日葡協会、1930年)(5) Centro de Estudos Históricos Ultramarinos, Boletim da Filmoteca Ultramarina Portuguesa, No. 47, Lisboa, 1986.
(6) Manuscritos da Ajuda (Guia), 2vols., Lisboa, 1966-73.
(7) António da Silva Rego, Jesuitas na Asia; Inventário e Indices, Lisboa, 1980.
(8)
箭内健次「ポルトガル・トルレ・ド・トンボ文書館所蔵『モンスーン』文書所収日本関係文書目録」(『史淵』第83輯、1960年)(9)
同「ポルトガル・トルレ・ド・トンボ文書館所蔵『モンスーン』文書所収極東関係文書目録」(『九州大学九州文化史研究所紀要』第8-9号、1961年)(10)
五野井隆史「リスボン市所在国立トーレ・ド・トンボ文書館収蔵『モンスーン文書 Livros das Moncoes』について」(『東京大学史料編纂所報』第11号、1976年)(11-A)
劉芳『漢文文書―葡萄牙國立東波塔档案館所蔵澳門及東方档案文献―』(澳門文化司署、1997年)(11-B) Isaú Santos e Lau Fong, ed., Chapas Sínicas; Macau e Oriente nos Arquivos Nacionais Torre do Tombo
(Documentos em Chinês), Instituto Cultural de Macau, Macau, 1997.(12) Isaú Santos, ed., Macau e Oriente; No Arquivo Histórico Ultramarino, 2vols., Lisboa, 1997.
(13) Boletim do Arquivo Histórico de Macau, No. 1, Jan-Jun. 1991.
(14) Luis Sanchez Belda, Guía de Fuentes para la Historia de Asia en Espana, Munchen, London, New York & Paris, 1987.
(15) María Victoria Alberola Fioravanti, Guía de la Biblioteca de la Real Academia de la Historia, Madrid, 1995.
(16) Joseph Franz Schütte, S. J., Documentos sobre el Japón conservados en la Coleccion <Cortes> de la Real Academia de la Historia-Madrid, Madrid, 1961.
(17) Joseph Franz Schütte, S. J., El <Archivo del Japón>, Madrid, 1964.
(18) Joseph Franz Schütte, S. J., Japon, China, Filipinas en la Colección
<Jesuitas Tomos> de la Real Academia de la Historia-Madrid, Madrid, 1976.
(19) Julian Paz, ed., Catálogo de Manuscritos de America existentes en Biblioteca Nacional, Madrid, 1992.
(20) Guía de la Exposición de Oriente-Occidente; Primitivas Relaciones en Espana, con Asia y Oceania, Madrid, 1958.
(21) Joseph Franz Schütte, S. J., “Documentos del <Archivo del Japon> en la Biblioteca Nacional madrirena”, Missionalia Hispanica, Ano XXVII, Num. 79, Madrid, 1970.
(22) Luis Sanchez Belda, Guía del Archivo Histórico Nacional, Madrid, 1989.
(23) Joseph Franz Schütte, S. J., “Documentos del <Archivo del Japón> en el Archivo Histórico Nacional de Madrid”, Missionalia Hispanica, Anos XXXV-XXXVI, Num. 103-108, Madrid, 1978-79.
(24) Angel de la Plaza Bores, Archivo General de Simancas: Guía del Investigador, Madrid, 1992.
(25) Jose María Pena y Camara, Archivo General de Indias de Sevilla: Guía del Visitante, Madrid, 1958.
(26) Pedro Torres y Lanzas & Francisco Navas de Valle, ed., Catálogo de los Documentos Relativos a las Islas Filipinas, existentes en el Archivo de Indias de Sevilla, (Pablo Pastells, S. J., Historia General de Filipinas) 9 vols., Barcelona, 1925-34.
2.3 WWWサーバを利用した歴史史料情報公開の今後の課題
鶴 田 啓
1.前提
歴史史料情報の
WWW公開を前提とした電子計算機システムSHIPS for Internet(以下、「現システム」)を導入して、約2年になろうとしている。現時点から振り返ると、WWW対応は当然のようであるが、現システムの準備期間、すなわち1995年頃の時点では、多くの所員にとって、WWWの世界はまだ実感できる環境ではなかった(1)。そのようななか、WWW対応を円滑に進めるための研究や条件整備を行う上で、本科学研究費の意味は少なくなかったと考えられる。(
1)93年以来ネットワークおよびメールのサーバーとしてUNIXワークステーションの稼働実績があったとはいえ、95年当時は、ようやく史料編纂所ホームページを立ち上げたところであり、ブラウザといっても、PCから利用できるのはtextオンリーのLynx(telnet経由)で、画像を見たければ、マシン室まで出かけて行ってMosaicを起動するしかなかった。それまで史料編纂所では、汎用機上の
DBMSにCOBOLアプリケーションを追加する形でシステムを拡張してきていた。しかし、1)数年間にわたる追加で、システム全体が複雑化していた、2)入力・校正や検索操作がDBごとに異なり統一性がない、3)DBアクセス・情報検索には、PC側にメーカー独自OSのエミュレータ(もしくは独自OS搭載の端末)が必要、4)画像関係では、画像ファイルサーバ・表示端末とも専用の機器が必要、などの問題点が明らかになってきていた。したがって、特定メーカーのハードやOSに依存せず、画像表示も可能なWWWという世界標準的な流れは、こうしたclosedな状況を打開する福音として受け止められた。また、公開検索に特化したシステムを用意することで、検索操作の単純化も可能だと考えられた。しかし、それまで使用していた汎用機には、
DBMSと連動して動くようなWWWサーバーアプリケーションは当時まだ存在しなかった。したがって、WWW対応を実現するためには、システム的に全く新規の追加部分が必要であり、その開発費や安定性を危惧する声が存在した。これについては、科研費により、一部DBを対象に先行して公開用DBを作成し評価を行った。また、WWW対応した際、ユーザーの認証・課金・ログ管理などをどうするのかという意見も存在した。これに関しては、結局、<WWW上にUPされているものは原則としてアクセス自由>という、いわばインターネットの精神を尊重して、できるだけシンプルな形で利用できる方針を取ることになった。
2.システムの運用上の障害
このようにして導入された現システムのうち、
WWWサーバーのOS・アプリケーション、およびそれと連動して動作する公開用DBサーバーのOS・アプリケーションは比較的安定した動作を示した。それに対して、画像表示系にはトラブルが頻発した。またネットワーク関係やPC関係でも少なからずトラブルが発生した。①
CD Serverの障害「
SHIPS for Internet」紹介の項にあるように、現システムでは、画像表示のためのCDを収めたチェンジャーを、Windows NTマシンであるCD Server(cliocd1・cliocd2)により制御している。このCD Serverは「見かけ上」UNIXのディレクトリ・ファイルとなるような形で、NFSマウントによりWWWサーバー(clioweb)配下に結ばれている。この部分のソフトウェアの出来に問題があったためか、あるいは、画像表示=CD-ROM読み出しの速度が遅いためか(レスポンスの遅さのため利用者が余分なクリック等を行った可能性もある)、「NFSマウントがはずれる」(エラーメッセージ:Stale NFS file handle)という障害がたびたび発生した。こうした事態に際しては、その都度、
1)NFSマウントのかけ直し、リブートで対処したほか、2)スレッド数を増加してマウントをかけ直す、3)Windows NT以下の再インストール、4)SmartCD Network Access for CDをインストール、5)Windws NTのバージョンアップ(3.51→4.0)などの手段を講じたが、本質的な解決には至らなかった。現状では、cliowebにHDDを増設し、ここに影写本画像のファイルをコピーすることで対処している。HDDのコストパフォーマンスは最近飛躍的に上がっているが、あまりスマートな解決法とは言えず、大容量の画像ファイルをどのようなデバイスに置くのが適当か、今後検討の余地があろう。②公開用データベース更新関係
公開用
DBの内容を更新するために汎用機上の入力・校正用元DBからDBサーバーへデータを転送する際、1)データが途中で切れてしまう、2)公開/非公開の指定がきかない等のエラーが発生し、原因究明に時間を要した。現状では、汎用機側の転送プログラム手直しにより解決されているが、転送元(汎用機側)のDBの一部に、1文字で3バイトを使用するメーカー拡張漢字が入っていいたため(人名等の固有名詞に使用)に発生したエラーであった。なお、元DBの拡張漢字部分は、公開用DBではゲタやコード表示になっている。③周辺機器・端末環境の信頼性
100Base-TXネットワーク系においては、1)サーバーのDNSダウン、2)ルーター・ハブのダウン、3)異常シャットダウン(予定停電前のシステムシャットダウンの際)といったトラブルが発生した。また、所内に配備した100台ほどのPC(Windows95マシン)においても、フリーズ、アプリケーション強制終了、ドライバ・メモリ不具合といったトラブルが、かなりの件数発生した。これらは、直接WWWサーバーにかかわることがらではないが、こうしたトラブルがシステム管理者の負担を増加させたことは否定できない。
④シャットダウン・再起動にともなう問題
東京大学では年に数回、土曜日もしくは日曜日に、電源系統の工事に伴う予定停電が実施される。そのような場合、システム全体のシャットダウンと再起動が必要となる
(2)。システムはもちろんUPSを備えているから、理屈上は、<停電→UPS作動→自動シャットダウン→復電→再起動>というサイクルも可能なはずであった。しかし実際には、CDサーバーのアンマウント/マウントや、ネットワークプリンタの終了/再起動などについては、マニュアルで確認しながら進める作業が必要であり、システム停止時間が長くなる(金曜日の夕方から月曜日の朝まで)原因になった。これらを含めてスケジューラで処理できれば、システム停止時間の短縮、管理者の負担軽減ができるので、次期システムにおいてはこのような機能が望ましいところである。(
2)汎用機系はスケジューラにより平日朝起動/夕方シャットダウンという運転管理をしているので、休日の停電は関係ない。
3.データ作成・公開をめぐる問題
上記2.は
WWWサーバ運用にともなう、電算機側の問題であったが、一方で、文書・画像情報公開に至る過程や、公開した情報(とくに文書画像)を取り扱うに際して生じる、いわば人間の側の問題も存在した。①画像リンクの作成
画像ファイルそのものは、仕様や「しきい値」の決定後一括して作成することができるが、ファイル名や
URL名などリンクの書き込みは、確認しながら手作業で行わなければならず、相当の労力を要した。今後、公開画像を増やして行くためには、ファイル名・URL名を、少なくとも半自動で付与できるような「仕掛け」が必要であろう。②原蔵者との関係
通常、古文書(写本を含む)の作成者は死没してから
50年以上経っているから、著作権は消滅しており、それをインターネット公開するとしても、法律上の著作権に抵触するような問題は発生しない。また、史料編纂所が国の業務として作成した写本(影写本・謄写本)の場合には、それに関わる諸権利は、国に帰属すると考えられる。ただ現実には、原文書の所蔵者が、文書の所蔵情報や(写本を含めた)画像公開の意義を十分に理解していないケースがある。法律上の問題にはならないとしても、史料編纂所の業務を進めて行く上で、史料所蔵者との良好な関係は不可欠であるから、そのような原文書所蔵者に対しては、
1)調査研究目的の利用であること、2)国や公的機関の業務内容や所蔵品をインターネット公開することが普遍的になってきている事情を説明し、理解が得られるように努力して行く必要がある。③利用者と利用管理の問題
インターネット通して公開している画像は、写真複成と比較すれば画質に相当の差があり、また近い将来画質が飛躍的に向上することもないと思われる(電話回線経由のアクセス速度の制約)。したがって、当面、公開した画像がそのまま影印版や写真版などの商業出版物に利用されるとは考えにくい。しかし、二次利用による問題が生じないとは言えず、またそのような場合、追跡調査が困難という問題点もある。たとえば、
DLした画像をもとに教材を作成して再配布するような場合でも、作成者の側から自発的な問合せや申請がなければ、史料編纂所側ではその存在を知ることができない。また、直接もしくは間接に文書画像を入手した研究者が、文面確認のために(別に他意はなかったとしても)原文書所蔵者のもとにそれを持ち込んで、問題を生じるといったケースもあり得る。本所の側でも、1)この公開が、原蔵者の理解と協力、史料採訪や複本作成業務の積み重ねにより成り立っていること、2)利用が許される基準・範囲があること、3)問合せの窓口・体制、などを明らかにして、利用者の理解と協力を求めるよう努めて行かなければならない。
4
. 次期システムのアウトラインと検討課題以上は現システム運用上の問題点から見た課題だが、同時に、次期システムの基本アウトラインと関わってくる諸問題についても、今後検討を進める必要がある。
①システムの構成
現システムでは、データの入力・校正を汎用機上で行い(新規に追加した
DBはPC上で作業)、その後DBサーバーにファイル転送している。汎用機には、1)安定した稼働実績、2)公開用と別系統のデータを持つという安心感、3)各DBのニーズに合わせて用意した印刷機能、といった特徴もあるが、限られた予算枠をどう有効に使うかということになれば、汎用機システムを持つことのメリット・デメリットを洗い直す必要がある。次期システムの構成において、汎用機のシステムが本当に必要かどうか、他のOS(Windows NTなりUNIXなり)上に、十分な安定・安全性を持ったDBシステムを、よりリーゾナブルに構築できるかどうか、研究して行かなければならない(3)。(
3)1998年、一部のDBにMS SQL Serverを試験導入したが、DBの件数が多いためか、チューニング不足のためか、あるいはソフトウェアの「デキ」が良くないためか、期待したパフォーマンスは出ていないようである。また、<汎用機→汎用機>といういわば平行移動ではなく、別個のプラットフォームへ従来の「作り込み」部分を移行させるとなれば、相応の開発費がかかることも、考慮すべきである。②性能基準の明確化
入札による調達制度の趣旨は、特定のハードやソフトを指定することではなく、われわれが必要とする性能値を明確化し、それに適合したハード・ソフトを調達することにある。しかし、従来のような、中央処理システムの
MIPS値やチャンネル数といった基準では、すでにシステム全体のパフォーマンスを十分に表せなくなっている。WWWサーバーやDBサーバーのログを解析して(信頼できる業者に解析させて)、スレッド数に対するリニアな追随性がどの辺まで必要か、TPM(Transactions per minute)の最高がどの程度必要かなど、適切な性能値を明確化して行く必要があろう。③ユーザーインターフェース
検索ユーザーの側から見た場合、本所のような公的機関が提供する情報検索ページには、
1)シンプルで軽いこと、2)セキュリティ上の危惧を与えないこと、3)原則として特定のソフトやversionに依存しないこと、といった特性が期待されるだろう(4)。しかし、このような原則を厳密に守ろうとすれば、利用可能文字や画面表示機能の制約が強くなる
(5)。HTMLに続く規格である・D-HTML XMLや、端末側で動作するスクリプト・アプレット類(Active Xなどは論外だが)をどの程度まで採用して行くか、利用者からのフィードバックを含めて見極めて行くことが課題である。(
4)インターネット上には、セキュリティのためブラウザのJava 受け入れを常にOFFに設定するユーザーもいれば、マシンにプリインストールされたMS Outlook Expressを初期設定のまま使用してHTMLメールを送付し、本人は訳の分からないまま周囲から顰蹙を買うようなユーザーもいる(筆者も最近被害にあった)。さまざまなレベルの利用者が混在することを、考慮しなければならない。(
5)現システムでも、ファイルサイズと画質の関係を考慮した結果、モノクロ画像についてはTIFF形式を採用しており、一部ブラウザではヘルパーAPが必要である。④情報提示のあり方
史料編纂所ではこれまで、主として、任意の言葉を入力して該当する史料を探す「キーワード型」アプローチにより、所蔵史料や既刊出版物情報の検索の便につとめてきた
(6)。ただ、現状では、本所の持つ史料情報(所蔵文書やこれまでの出版物)全体のなかで、どの部分が公開されており、どの部分が公開されていないかについて、わかりにくい面があることは否定できない。史料(群)の性格や内容についてのガイダンスをたどることで目的の史料に到達できる「目録型(キャビネット・フォルダ型と言ってもいい)」アプローチを用意し──誰がそのための作業をするかという大きな問題はあるが──両面からのアプローチを可能にすることも検討しなくてはなるまい。(
6)実際には、史料情報だけではなく、調査・編纂・出版など業務の諸過程で発生するさまざまな歴史史料情報も含んでいる。⑤文字コードの問題
現在メジャーなブラウザは、文字コードセットの切り替え機能を持っており、また各コードセットで使用する表示フォントを指定することができる。したがって、海外の日本史研究者でも、日本語の表示用フォントを用意すれば、日本語ホームページの閲覧(印刷用の日本語フォントがあれば印刷も)が、一応は可能である。ただしこの場合、見る先によってコードセットを切り替える必要があることや、1台のマシン(もしくは
HDDの1起動領域)をその言語専用にしてしまわなければ、データとしての意味を持たないという不便がある。文字コードの拡張については、以前から東洋学関係の団体を中心にいくつかの規格が提起されているほか、JISの拡張も具体化しており、また
Windows NTの次期バージョンで
は、
unicodeによって(いろいろと問題は指摘されているが)世界的に文字コードの統一が可能になるとアナウンスされている。本所としても、各種の動向に注意を払っているが、今後どのような規格が主流になっていくのか、見通すことができないのが現状である。
以上あげてきたように、現システムから次期システムへと向けて、課題は山積している。さらに、本科研の趣旨からは少しはずれるため、ここでは触れなかったが、一番の問題は
DB作成のための労力や資金をどう確保するかという点である。限られたコスト・人間・時間のもとで、実際にどこまで問題の解決が可能か、はなはだ心もとない面もあるが、歴史史料情報のWWW公開を進めるため、今後も工夫と努力を継続して行きたい
WWWサーバによる日本史データベースの
マルチメディア化と公開に関する研究
1996年度~1998年度 科学研究費補助金 基盤研究(A)(2) 研究成果報告書
1999年3月31日 発行
編集・発行
加藤 友康東京大学史料編纂所
東京都文京区本郷
7丁目3番1号電話
03(3812)2111(代表)印刷・製本 有限会社
日本興業社